Tai Tham Updated, Thai Noi Revisited
Update งานอักษรอีสาน
Khottabun กับอักษรธรรมแบบไร้ USE
หลังจากการวิเคราะห์ทางเลือกต่างๆ สำหรับอักษรธรรมไป 2 blog (Lao Tham Font vs USE และ To USE or Not to USE for Lao Tham) และได้ตัดสินใจ หลีกเลี่ยง USE โดยยอมทิ้ง MS Word ไว้ข้างหลัง ก็ได้ implement ใน fonts-khottabun ตามนั้น ตั้งแต่ commit a0389bd จนถึง commit 1c73c80 โดยปรับ major version ของฟอนต์ขึ้นเป็นรุ่น 003 สำหรับอักษรธรรมแบบไม่ใช้ USE
Keyboard Layout อักษรธรรมบน Windows
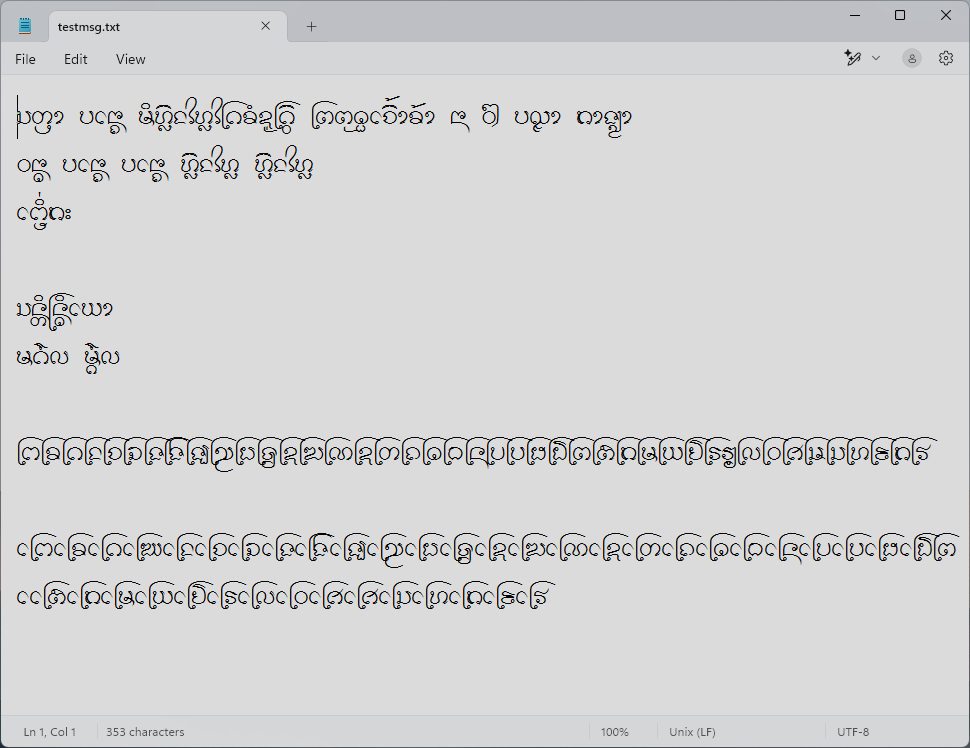
ถัดมาคือ ผังแป้นพิมพ์อักษรธรรมบน Windows ในรูปของซอร์ส KLC สำหรับสร้างเป็นผังแป้นพิมพ์ด้วย Microsoft Keyboard Layout Creator (MSKLC) 1.4 ซึ่งจะ build เป็น DLL พร้อมโปรแกรม setup
ประเด็นปลีกย่อยของผังนี้คือ Windows กำหนดให้ผังแป้นพิมพ์ต้องผูกติดกับโลแคล (locale) ซึ่งกำหนดด้วยภาษาและดินแดน ตรงนี้เป็นปัญหาโดยนิยามอยู่ เพราะอักษรธรรมสามารถใช้เขียนได้หลายภาษา ไม่ว่าจะไทย ลาว ไทลื้อ ไทขึน หรือคาถาบาลี-สันสกฤต แต่ Windows จะบังคับให้เราเลือกเพียงภาษาเดียวมาประกอบกับดินแดนที่เป็นถิ่นของภาษาที่ใช้ โดยห้ามใช้ซ้ำกับผังอื่นในโลแคลนั้นๆ ด้วย ประเด็นคือ:
- โลแคลต่างๆ มักมีผังแป้นพิมพ์อยู่แล้ว ถ้าไม่ต้องการซ้ำก็ต้องสร้างโลแคลใหม่สำหรับอักษรธรรม แต่จะกำหนดโลแคลด้วยภาษาอะไร ในเมื่ออักษรธรรมสามารถใช้เขียนได้หลายภาษา?
- สมมุติว่าเราเลือกสร้างโลแคลภาษาลาวถิ่นไทย (
lo-TH) ด้วย Microsoft Locale Builder แต่ปัญหาคือ เราไม่สามารถเลือกบล็อคยูนิโคดของอักษรธรรมให้กับโลแคลใหม่นี้ได้ เนื่องจาก Microsoft กำหนดตัวเลข enum ให้กับบล็อคยูนิโคดต่างๆ แต่ยังไม่ได้กำหนดเลขสำหรับอ้างให้กับบล็อคอักษรธรรม! - ในเมื่อสร้างโลแคลเองไม่ได้ วิธีแก้ขัดจึงเป็นการเลือกโลแคลอะไรก็ได้ที่ไม่ซ้ำกับชุดผังแป้นพิมพ์ที่เราใช้ เช่น ใช้ th, en ไม่ได้ เพราะจะซ้ำกับสองผังหลักที่เราใช้ และผมก็จิ้มเอาโลแคลมลยาฬัมในอินเดีย (
ml-IN) โดยไม่มีเหตุผลใดๆ มากไปกว่าการแก้ขัด เวลาจะป้อนอักษรธรรมบน Windows ผู้ใช้ก็สลับแป้นพิมพ์ไปที่ภาษามลยาฬัม - อันที่จริง สิ่งที่เราต้องการมากกว่าในกรณีนี้คือการอ้างถึง
อักษร
(script) ตรงๆ ไปเลย แต่การออกแบบของ Windows ยังไม่เอื้อขนาดนั้น
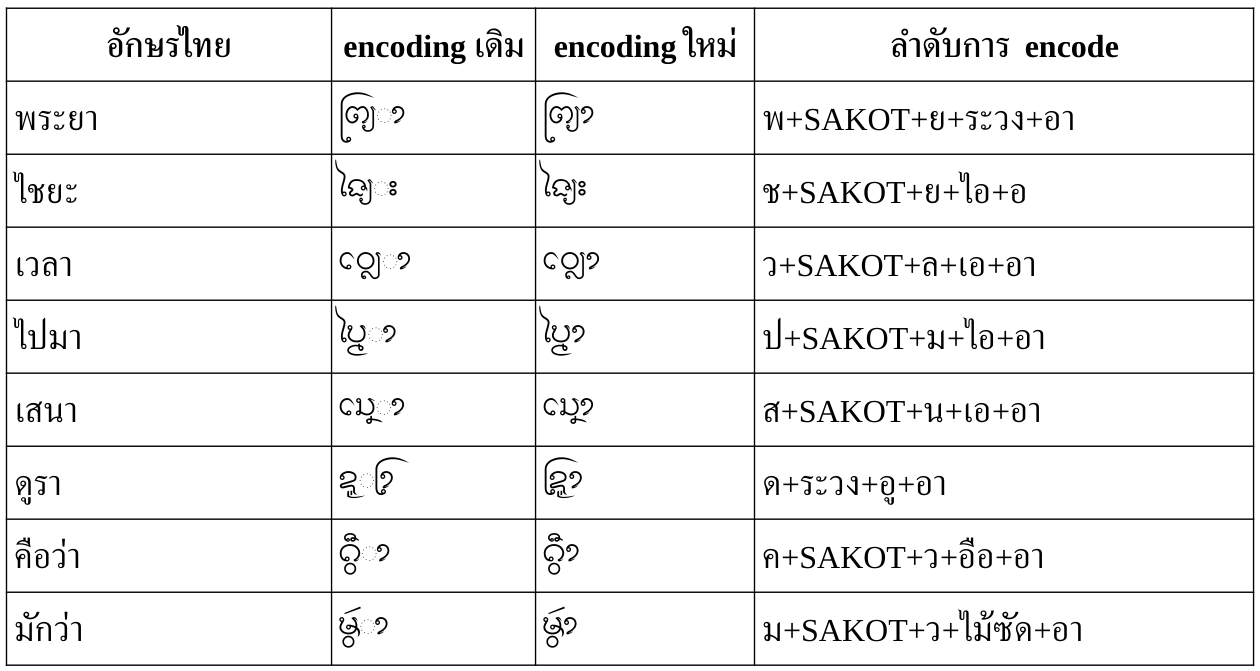
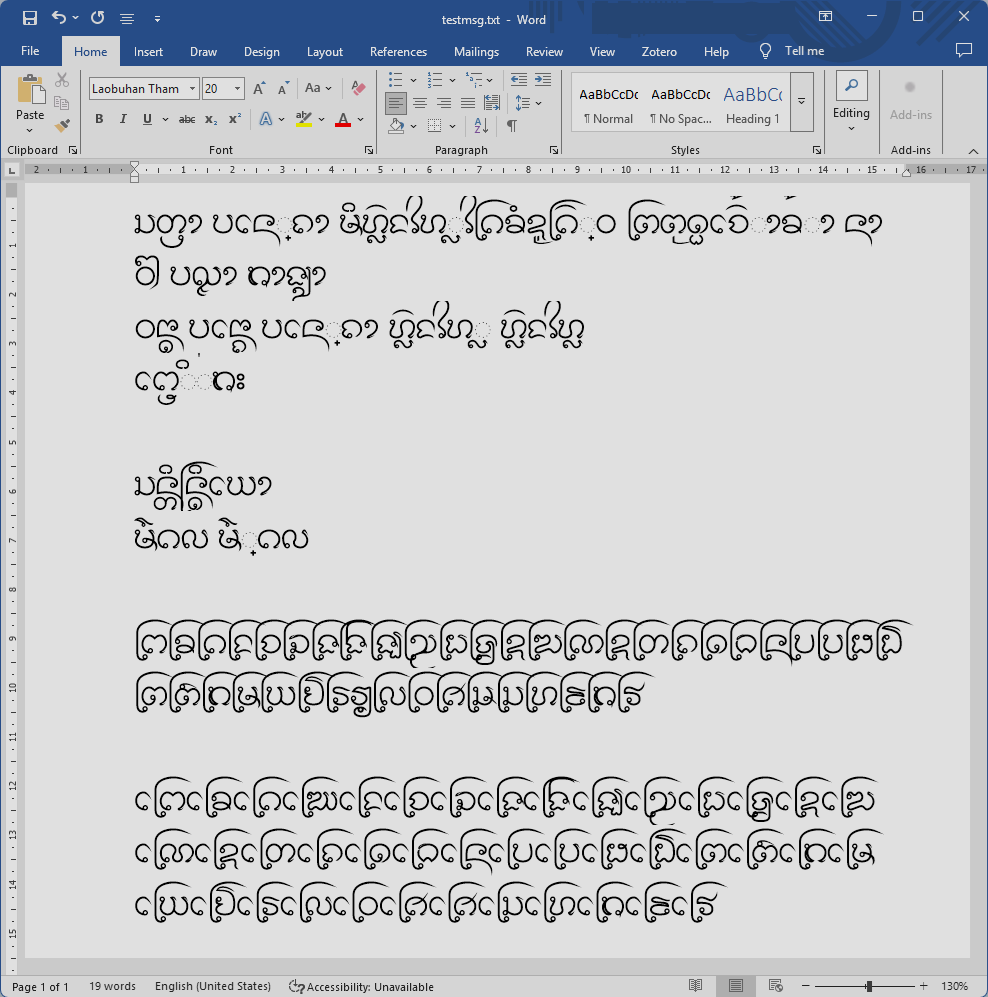
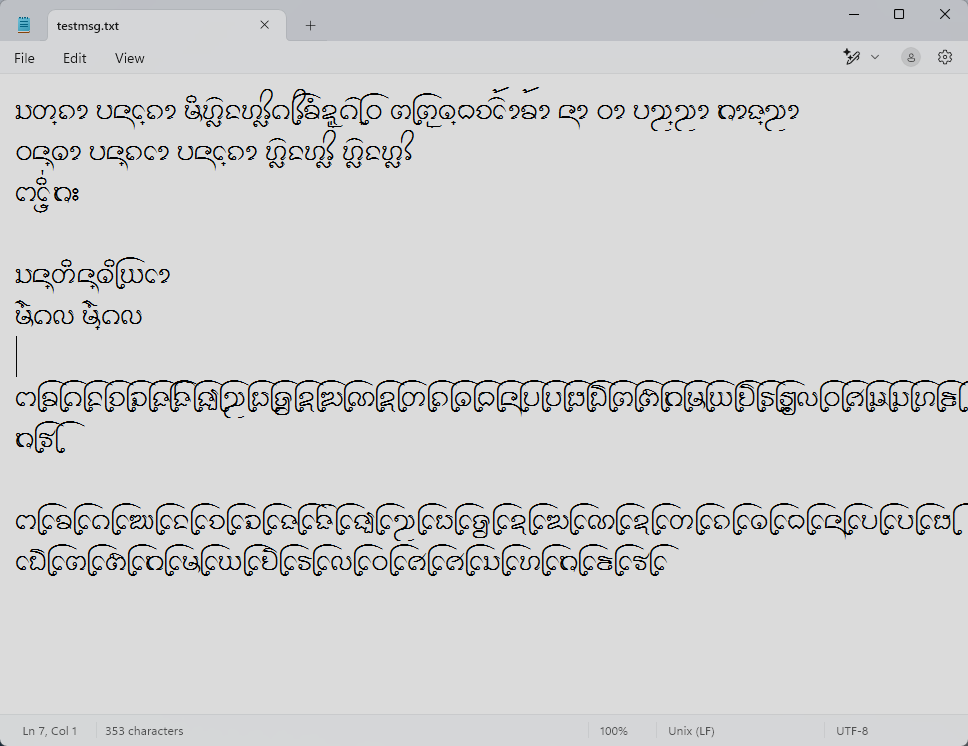
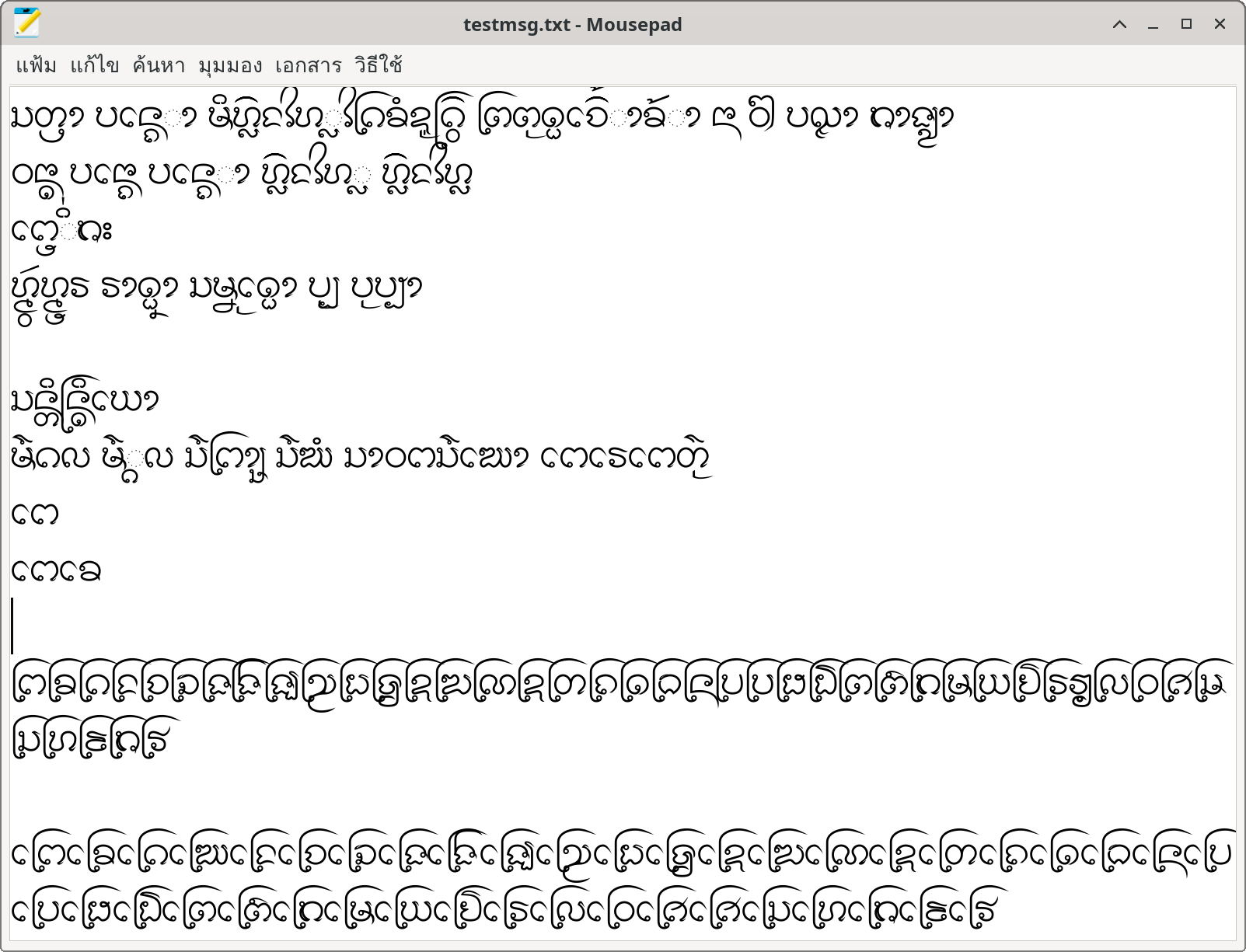
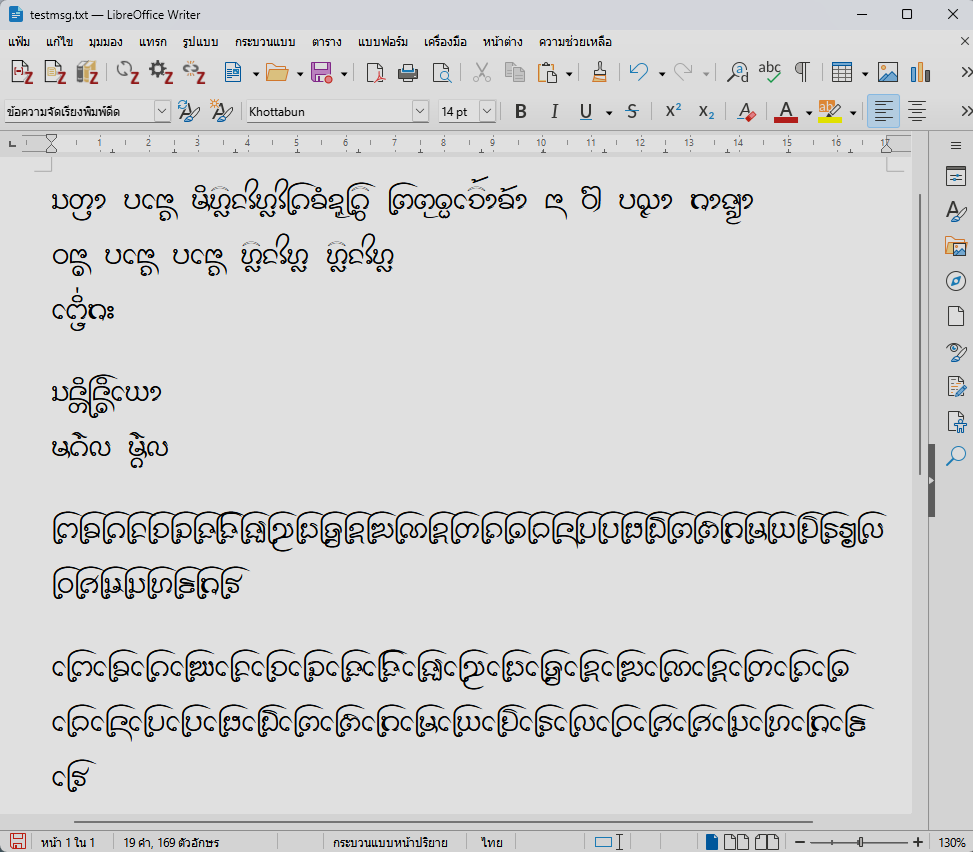
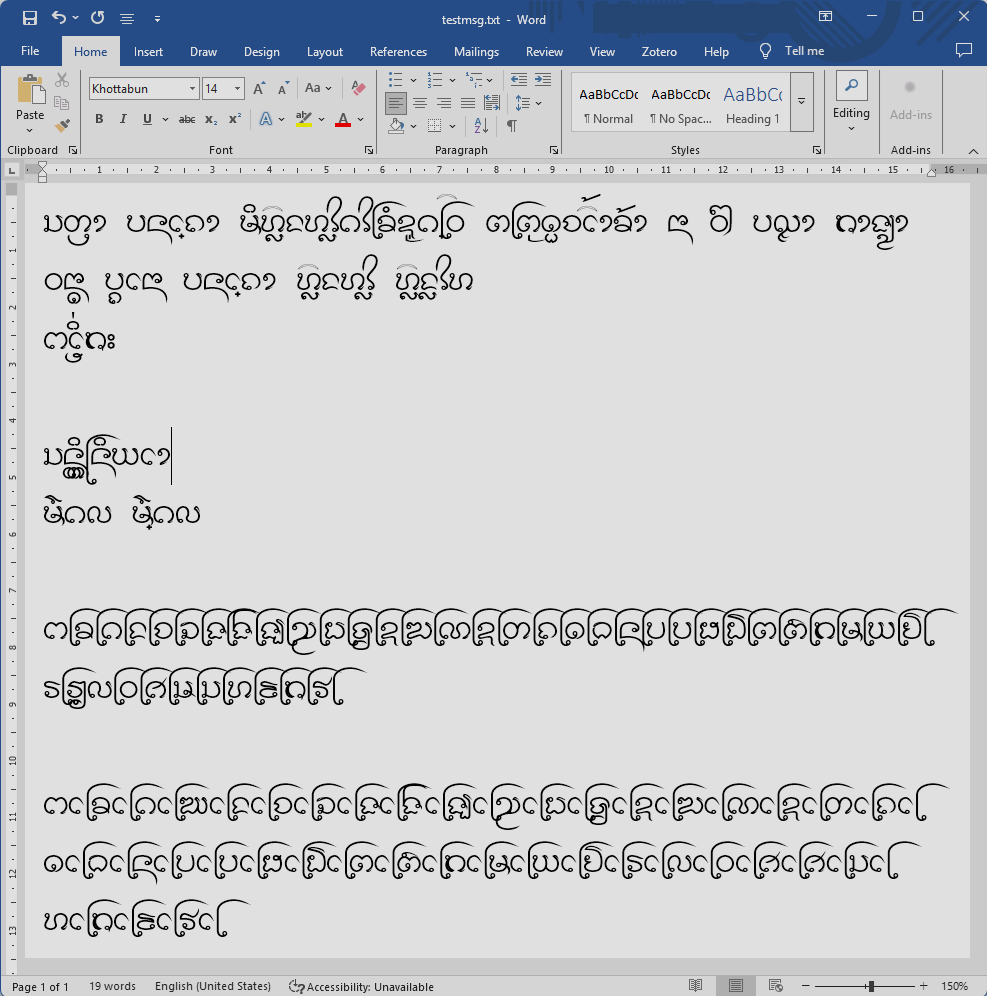
อย่างไรก็ดี เราก็ได้ผังแป้นพิมพ์อักษรธรรมที่ทำงานได้บน Windows โดยเป็นเพียงผังปุ่มจริงๆ ยังไม่มีการตรวจหรือสลับลำดับอะไร ผู้ใช้ต้องป้อนตามลำดับยูนิโคดเป๊ะๆ เช่น ᨸᩮᩢ᩠ᨶ (เป็น) ก็ต้องป้อนเป็น ป + เอ + ไม้ซัด + SAKOT + น
อักษรไทยน้อย
แม้อักษรไทยน้อยจะเรียบง่ายกว่าอักษรธรรม แต่กลับมีรายละเอียดปลีกย่อยมากกว่า ทั้งเรื่องความหลากหลายของชุดอักษรที่ใช้ การควบอักษรติดกัน การยืมตัวห้อยตัวเฟื้องจากอักษรธรรมตามแต่ผู้จารึกจะเลือกใช้ ดังที่ผมได้เคย สรุปประเด็น ไว้ โดยยังไม่ตกลงว่าจะเลือก implement แบบไหน
เมื่อหลายปีก่อน ในระหว่างที่ทำไปศึกษาไปนั้น ผมเลือกที่จะเติมอักขระลงในช่องที่ยังว่างอยู่ของบล็อคยูนิโคดอักษรลาว ไม่ว่าจะเป็นตัวเฟื้องหรือตัวควบต่างๆ แต่ยิ่งพบอักขระที่ต้องเพิ่มรหัสมากขึ้นจากการอ่านจารึก ก็ยิ่งเห็นว่ามันไม่ใช่วิธีที่ดีในระยะยาว
ตอนนี้ได้โอกาสมาปัดฝุ่น โดยบล็อคยูนิโคดลาวเองก็มีมีการเพิ่มอักขระสำหรับเขียนภาษาบาลีตามแบบพุทธบัณฑิตสภา จึงได้พิจารณาทางเลือกต่างๆ ใหม่
เริ่มจากตรวจสอบความคืบหน้าใน Unicode ของอักษรไทยน้อย ซึ่ง ข้อมูลใน ScriptSource ของ SIL ได้บันทึกรายละเอียดไว้ โดยสถานะล่าสุดคือ ยังไม่กำหนดใน Unicode ส่วนกระบวนการเท่าที่ผ่านมาคือ
- 2018-01-02 Request to Add Thai Characters — Nitaya Kanchanawan (WG2 N4927, L2/18-041)
- เป็นข้อเสนอขอเพิ่มอักขระไทยน้อยลงในบล็อคอักษรไทย! โดยเป็นงานที่เกี่ยวเนื่องกับการกำหนดมาตรฐานการถอดอักษรไทยน้อยเป็นอักษรโรมันที่ราชบัณฑิตยสภาได้เสนอเข้าสู่ ISO/IEC โดยได้รับความเห็นว่าควรกำหนดรหัสอักขระก่อน แต่ไม่ทราบว่าด้วยเหตุผลใด ราชบัณฑิตยสภาถึงได้เสนอให้เพิ่มอักขระในบล็อคอักษรไทยแทนที่จะเป็นบล็อคอักษรลาวที่อยู่ในสายวิวัฒนาการโดยตรง
- 2018-01-19 Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 / WG3 (WG2 N4927A, L2/18-042)
- เป็นร่างมาตรฐานการถอดอักษรไทยน้อยเป็นอักษรโรมันที่เป็นต้นเรื่อง ตัวเอกสารต้องใช้รหัสผ่านในการเข้าถึง และไม่เกี่ยวข้องกับเรื่องรหัสอักขระโดยตรง ผมจึงไม่ใส่ลิงก์ไว้
- 2018-01-19 Results on ISO CD 20674-1: Information and documentation - Transliteration of scripts in use in Thailand - Part 1: Transliteration of Akson-Thai-Noi — TC46 Secretatriat (WG2 N4927B, L2/18-043)
- ผลการโหวตร่างมาตรฐานการถอดอักษรไทยน้อยของคณะกรรมการ เห็นชอบ 16, เห็นชอบโดยมีข้อคิดเห็น 2, ไม่เห็นชอบ 1, งดออกเสียง 19
- 2018-02-20 Thai-Noi Transliteration — Martin Hosken (WG2 N4939, L2/18-068)
- เป็นความเห็นจากคุณ Martin Hosken ผู้เชี่ยวชาญจาก SIL โดยสรุปเห็นว่าอักษรไทยน้อยเข้ากันได้กับอักษรธรรมมากกว่าอักษรไทย
- 2018-02-28 Towards a comprehensive proposal for Thai Noi / Lao Buhan script — Ben Mitchell (L2/18-072)
- เป็นความเห็นจากคุณ Ben Mitchell ผู้เชี่ยวชาญอีกท่านหนึ่ง โดยมีผู้ร่วมให้ข้อมูลคือ Patrick Chew, ผมเอง และ อ.ประพันธ์ เอี่ยมวิริยะกุล โดยสรุปเห็นว่าควรเพิ่มอักขระไทยน้อยในบล็อคอักษรลาว โดยเพิ่มเติมจากอักษรลาวบาลีของพุทธบัณฑิตสภาอีกที และได้เสนอทางเลือกต่างๆ ดังที่ผมได้สรุปไว้ แต่ยังไม่ระบุว่าจะเลือกวิธีการไหน
- Recommendations to UTC #155 April-May 2018 on Script Proposals (L2/18-168) (อยู่ที่ข้อ 6.) และบันทึกการประชุมของ UTC #155 (L2/18-115) (อยู่ที่ข้อ D.8.1 และ D.8.3)
- สรุปข้อแนะนำของคณะกรรมการว่าอักษรไทยน้อยไม่ใข่ส่วนขยายของอักษรไทย และผู้เสนอร่างอักษรไทยน้อย (หมายถึง อ.นิตยา กาญจนวรรณ จากราชบัณฑิตยสภา) ควรนำข้อมูลในเอกสารของคุณ Ben Mitchell ข้างต้นไปใช้ประกอบการร่างด้วย โดยมอบให้ Deborah Anderson ร่างเอกสารแจ้งเจ้าของร่าง ซึ่งก็คือเอกสาร L2/18-070
แล้วกระบวนการทั้งหมดก็หยุดอยู่ที่รอการดำเนินการของราชบัณฑิตยสภาต่อจากนั้น
สรุปว่ายังไม่มีมาตรฐาน Unicode อักษรไทยน้อยเกิดขึ้น ถ้าจะ implement ตอนนี้ก็เป็นเพียงตุ๊กตาเท่านั้น
จากทางเลือกต่างๆ ที่มี ผมพิจารณาเลือกเองไปก่อนอย่างนี้:
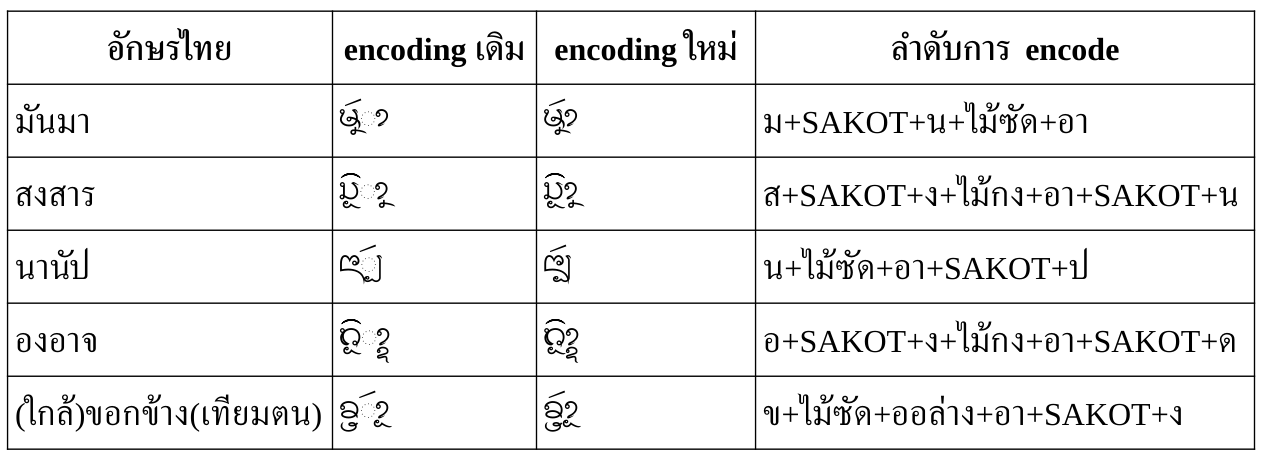
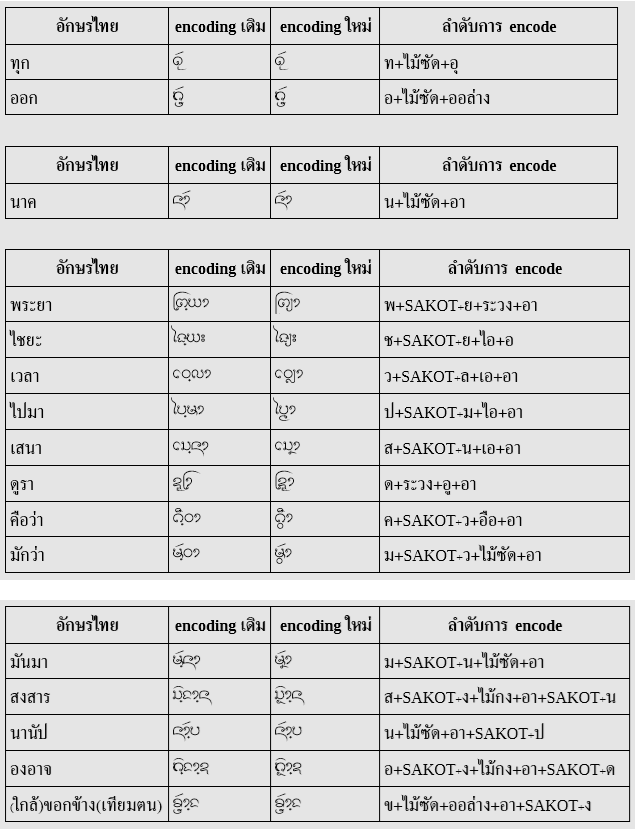
- Conjunct หรือการสังโยคพยัญชนะด้วยตัวห้อย/ตัวเฟื้อง ใช้พินทุ (U+0EBA LAO SIGN PALI VIRAMA) ตามด้วยพยัญชนะที่จะสังโยค ยกเว้นกรณีที่มีรหัสอยู่แล้ว คือ ล ห้อย (U+0EBC) และ ย เฟื้อง (U+0EBD) ก็ใช้รหัสนั้นๆ ไปเลย
- Ligature หรือตัวแฝด หรืออักษรควบ ใช้ U+200D ZERO WIDTH JOINER (ZWJ) เชื่อมพยัญชนะ ยกเว้นกรณีที่มีรหัสอยู่แล้ว คือ U+0EDC (ໜ), U+0EDD (ໝ) ก็ใช้รหัสนั้นๆ ไปเลย
- สระออย กำหนดอักขระใหม่ในช่องที่ยังว่างอยู่ คือ U+0EBE เพื่อให้เป็นวิธีที่สอดคล้องกับอักษรธรรม (อีกวิธีที่ไม่ต้องกำหนดอักขระใหม่คือใช้ พินทุ + ຢ แต่จะเป็นวิธีที่แปลกแยกจากอักษรธรรม)
เมื่อเลือกวิธีนี้แล้ว ก็ปรับเปลี่ยนทั้งในฟอนต์ Khottabun และในระบบป้อนข้อความ Lanxang ดังนี้:
-
fonts-khottabun: detach glyph ตัวห้อย/ตัวเฟื้องและตัวควบทั้งหมดจากรหัสอักขระ แล้วสร้างกฎ'ccmp' TN conjunctsและ'ccmp' TN subjoinsเพื่อเข้าถึง glyph เหล่านี้ผ่านพินทุและ ZWJ ตามลำดับ พร้อมกับปรับรุ่น major ของฟอนต์เป็นรุ่น004(commit cc4935a) -
lanxang: ตัดกระบวนการแปลงพินทุ + พยัญชนะ
เป็นอักขระตัวห้อย/ตัวเฟื้อง และพยัญชนะ + ZWJ + พยัญชนะ
เป็นอักขระตัวควบ ทั้งหมด (ทิ้ง sequence ประกอบไว้อย่างนั้นในข้อความเลย แล้วให้ฟอนต์จัดการตอน render) ยกเว้นการควบ ໜ,ໝ เพื่ออำนวยความสะดวก (commit f0645b1) แต่ก็ยังป้อน ໜ, ໝ โดยตรงได้ด้วย level 3 เช่นกัน -
lanxang: เพิ่มผังแป้นพิมพ์อักษรไทยน้อยสำหรับ Windows ด้วย (commit cce81cd)
พร้อมกันนี้ก็แปลงวิธีลงรหัสอักขระไทยน้อยในตัวอย่างการปริวรรตทั้งหลายด้วย (พญาคันคาก, ฮีตคองคะลำ, บูชาพญานาค, นกกระจอก)
ป้ายกำกับ: ibus, thainoi, tham, typography, unicode
บันทึกโดย Thep ณ
16:46
0 ความเห็น
![]()