Lanxang Project
กลับมาพูดถึง โครงการอักษรอีสาน อีกครั้ง โครงการนี้ถ้านับตั้งแต่เริ่มวางแนวคิด ตอนนี้ก็อายุได้ 2 ปีเต็มพอดี ที่ผ่านมาก็ได้ทำ ฟอนต์โคตรบูรณ์ โดยใช้ฟอนต์ อ.สานิตย์ เป็นฐาน เอามาปรับให้เป็นยูนิโค้ด และเพิ่มกฎ GSUB ในระหว่างที่ rendering engine ต่าง ๆ ยังไม่รองรับ
ความคืบหน้าล่าสุด หลังจากที่ได้ตั้งกลุ่มทำงานอักษรอีสานร่วมกับคุณอันธิฌาและคุณเสกสรร ก็ได้เพิ่มความเข้มข้นในการศึกษาจารึกโบราณมากขึ้น โดยในระหว่างปริวรรตจารึกลงเว็บ ก็พบความไม่สะดวกในการป้อนข้อความตาม phonetic order ของยูนิโค้ด และเนื่องจากทีมงานเริ่มมีความเข้าใจอักษรธรรมกันพอสมควรแล้ว จึงได้ประชุมกันออกแบบ input method สำหรับอักษรธรรมลาว/อีสาน
โค้ดอยู่ใน github โดยใช้ชื่อโครงการว่า ล้านช้าง โดย input method นี้จะมีคุณสมบัติดังนี้:
- มีผังแป้นพิมพ์ในตัว โดยดัดแปลงจากผัง มอก. 820-2538
- สลับลำดับการพิมพ์ เพื่อให้ผู้ใช้สามารถป้อนข้อความในลำดับจากซ้ายไปขวาเหมือนอักษรไทย แล้ว input method จะสลับลำดับให้เป็น phonetic order ตามข้อกำหนดยูนิโค้ดให้
- ตรวจลำดับการพิมพ์ คล้าย วทท. 2.0 โดยสามารถปรับแต่งระดับความเข้มงวดของการตรวจสอบได้ 3 ระดับ คือปล่อยผ่าน, ตรวจสอบขั้นพื้นฐาน (สามารถป้อนตัวสะกดแบบพิเศษได้) และตรวจสอบแบบเข้มงวด (ไม่อนุญาตตัวสะกดแบบพิเศษ)
ผังแป้นพิมพ์จะเป็นแบบนี้:

ส่วนตารางการตรวจลำดับที่ได้จากการออกแบบร่วมกันของทีมงาน จะเริ่มจากการแบ่งคลาสของอักขระดังนี้:
- LV = สระหน้า
- AV = สระบน (อิ อี อึ อื ไม้กง ไม้เกาห่อนึ่ง)
- AD1 = ตัวสะกดบน (ไม้ซัด ไม้อังแล่น)
- AD2 = ตัวสะกดบน/สระบน (นิคหิต)
- BV1 = สระล่าง 1 (อุ อู)
- BV2 = สระล่าง 2 (ออล่าง)
- FV1 = สระหลัง 1 (อะ)
- FV2 = สระหลัง 2 (อา อาสูง)
- FV3 = สระหลัง 3 (ออย)
- IV = สระลอย (อิ อี อุ อู เอ โอ ลอย, ฤ ฦ)
- C1 = พยัญชนะที่เฟื้องด้วยพินทุได้
- C2 = พยัญชนะที่เฟื้องด้วยพินทุไม่ได้ (ฃ ฅ ซ ฝ ฟ หยอหยาดน้ำ ร ล ฬ อ ฮ สอสองห้อง)
- PH = พินทุ (SAKOT)
- S1 = เฟื้องพิเศษ 1 (ระวง)
- S2 = เฟื้องพิเศษ 2 (ล เฟื้องล่าง, ล เฟื้องข้าง)
- T = วรรณยุกต์
- LG = ตัวประสม (แล)
- CR = ตัวรหัสลับ (cryptogram)
- NP = ตัวเลขและเครื่องหมายวรรคตอน
จากนั้น ก็จะพิจารณาการกระทำระหว่างอักขระที่อยู่หน้าเคอร์เซอร์กับอักขระที่กด โดยกำหนดรหัสการกระทำดังนี้:
- P = เข้าสู่ pre-edit mode
- A = รับอักขระ
- W = รับอักขระโดยสลับกับอักขระก่อนหน้า
- R = ไม่รับอักขระ
- S = ไม่รับอักขระในโหมดเข้มงวด รับอักขระในโหมดปกติ
และพิจารณาการกระทำจากตารางนี้:
| c0,c1 | X | L V | A V | A D 1 | A D 2 | B V 1 | B V 2 | F V 1 | F V 2 | F V 3 | I V | C 1 | C 2 | P H | S 1 | S 2 | T | L G | C R | N P |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| X | R | P | R | R | R | R | R | R | R | R | A | A | A | R | R | R | R | A | R | A |
| LV | R | P | A | A | S | S | S | A | A | S | A | A | A | A | W | A | A | A | A | A |
| AV | R | P | R | R | A | R | A | S | A | S | A | A | A | A | R | A | A | A | A | A |
| AD1 | R | P | R | R | R | R | R | S | S | S | A | A | A | A | R | A | A | A | A | A |
| AD2 | R | P | R | R | R | R | R | S | A | S | A | A | A | S | R | R | A | A | R | A |
| BV1 | R | P | S | A | A | R | R | S | S | S | A | A | A | S | A | R | A | A | R | A |
| BV2 | R | P | R | A | R | R | R | A | R | R | R | A | A | S | R | R | A | A | R | A |
| FV1 | R | P | R | R | R | R | R | R | R | R | A | A | A | R | R | R | R | A | R | A |
| FV2 | R | P | R | A | R | R | R | A | R | R | A | A | A | A | R | A | R | A | A | A |
| FV3 | R | P | R | R | R | R | R | R | R | R | A | A | A | R | R | R | R | A | R | A |
| IV | R | P | A | R | R | R | R | R | R | R | R | A | A | R | R | R | R | A | R | A |
| C1 | R | P | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A |
| C2 | R | P | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A | A |
| PH | R | P | R | R | R | R | R | R | R | R | R | A | R | R | R | R | R | R | R | R |
| S1 | R | P | A | A | A | A | A | A | A | A | A | A | A | A | R | R | A | A | A | A |
| S2 | R | P | A | A | A | A | S | A | A | A | A | A | A | S | R | R | A | A | A | A |
| T | R | P | R | R | R | R | R | A | A | A | A | A | A | A | R | R | R | A | A | A |
| LG | R | P | R | R | R | R | R | A | R | R | A | A | A | A | R | R | A | A | A | A |
| CR | R | P | A | A | A | A | A | A | A | A | A | A | A | S | A | A | A | A | A | A |
| NP | R | P | R | R | R | R | R | R | R | R | A | A | A | R | R | R | R | A | R | A |
ตารางการกระทำในโหมด pre-edit:
| P | X | L V | A V | A D 1 | A D 2 | B V 1 | B V 2 | F V 1 | F V 2 | F V 3 | I V | C 1 | C 2 | P H | S 1 | S 2 | T | L G | C R | N P |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LV | R | R | R | R | R | R | R | R | R | R | R | C | C | R | R | R | R | R | R | R |
การกระทำ C = commit อักขระใน pre-edit string โดยกลับลำดับจากหลังมาหน้า
ขณะนี้ engine สำหรับ IBus เริ่มใช้การได้แล้ว โดยกำลังอยู่ระหว่างทำ GUI สำหรับตั้งค่า:
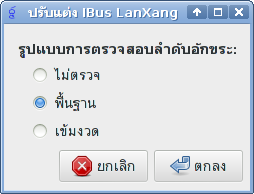
สำหรับตอนนี้อาจใช้ IBus เป็นหลัก แต่ในอนาคตก็อาจพิจารณาเพิ่ม engine สำหรับ framework อื่นตามความจำเป็น
ว่าแล้วก็ทดสอบ input method สักหน่อย:
ᨹᩲᩅᩣᨾᩮᩨᩬᨦᩎᩈᩣ᩠ᨶᩌᩣ᩠ᨦ ᩈᩥᨧᩪᩙᨡᩯ᩠ᨶᨾᩢ᩠ᨶᨸᩲᨷᩮᩥ᩠ᨦ
ᨠᩫ᩠ᨠᩋᩭᨿᩢ᩠ᨦᩈ᩠ᩅ᩠ᨿᩃ᩠ᩅ᩠ᨿ ᨠᩫ᩠ᨠᨠᩖ᩠ᩅ᩠ᨿᨿᩢ᩠ᨦᩈᩣ᩠ᨿᩃᩣ᩠ᨿ
ᨾᩢ᩠ᨶᩈᩥᩌᩣ᩠ᨦᨷᩬᩁᨧᩢ᩠ᨦᨯᩲ
(จะอ่านได้ ก็ติดตั้งฟอนต์ ก่อนนะครับ และควรเปิดด้วย Firefox หรือ IE9 จึงจะอ่านเป็นคำ ส่วน Chrome และเบราว์เซอร์ที่ใช้ WebKit ทั้งหมดนั้น ยังแสดงผลผิดลำดับ อ่านไม่เป็นคำครับ)
ป้ายกำกับ: ibus, language, localization, tham
บันทึกโดย Thep ณ
16:57
![]()






0 ความเห็น:
แสดงความเห็น (มีการกลั่นกรองสำหรับ blog ที่เก่ากว่า 14 วัน)
<< กลับหน้าแรก