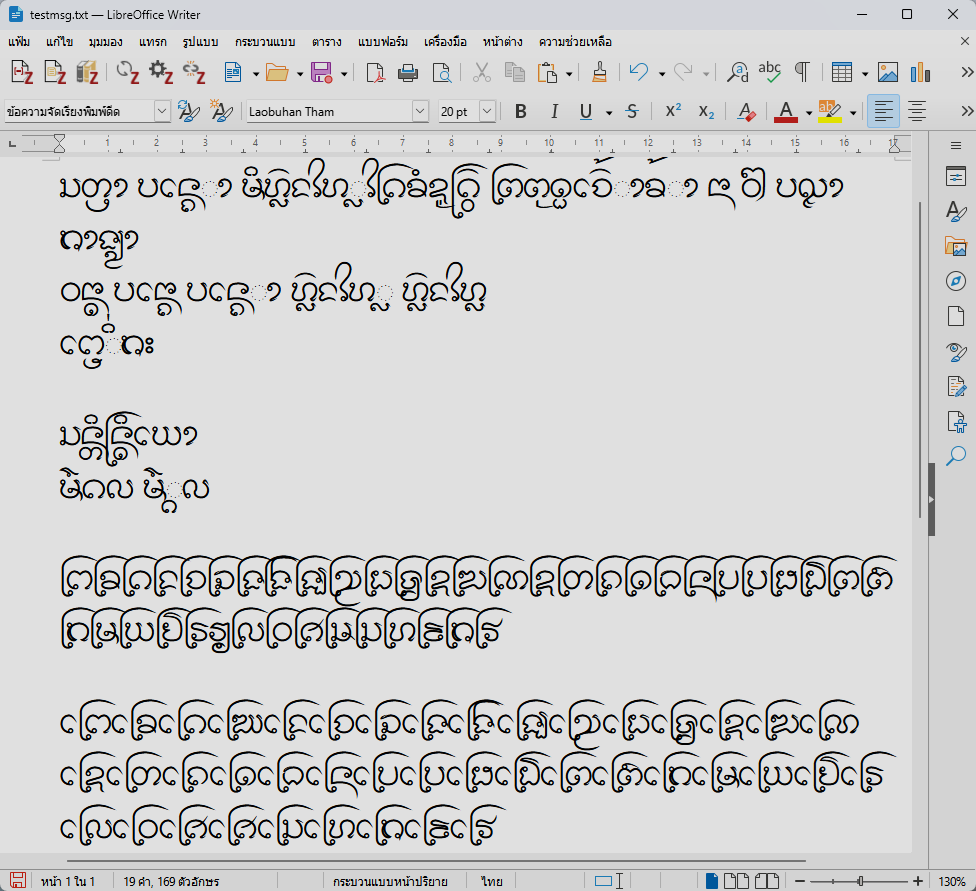
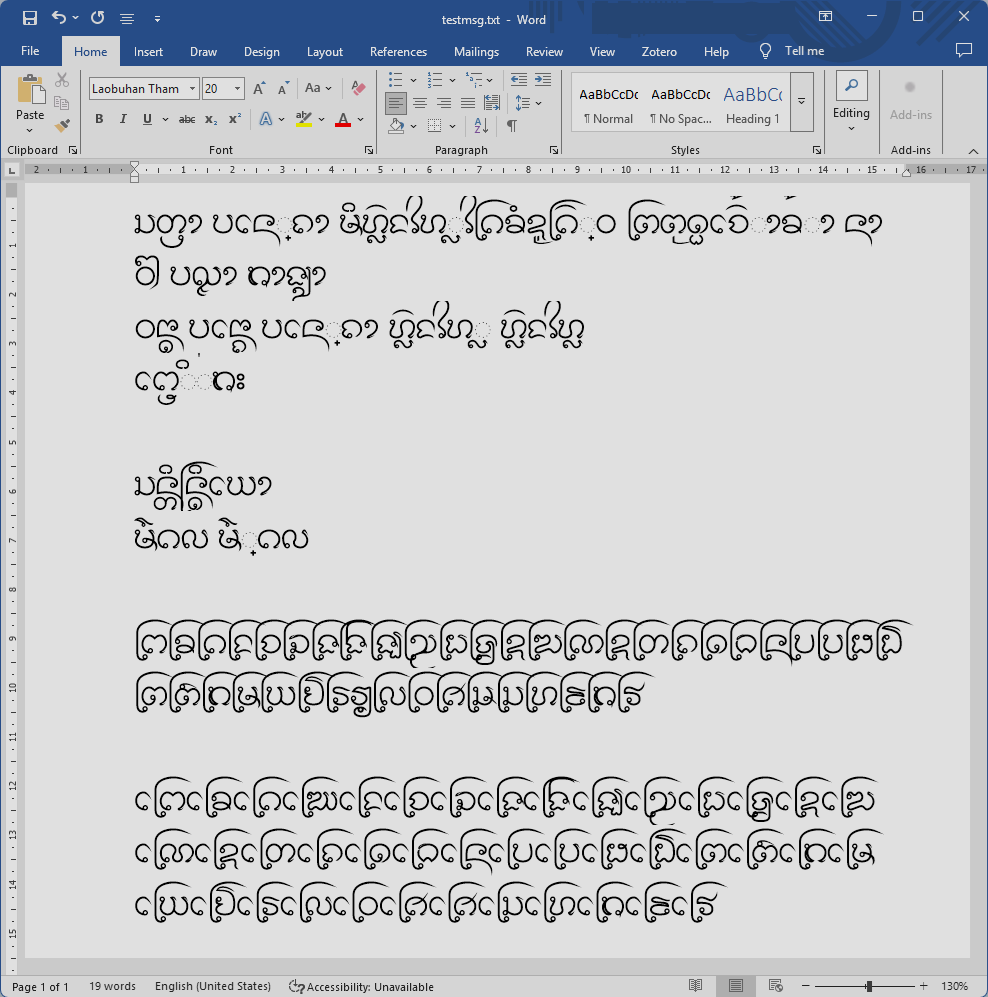
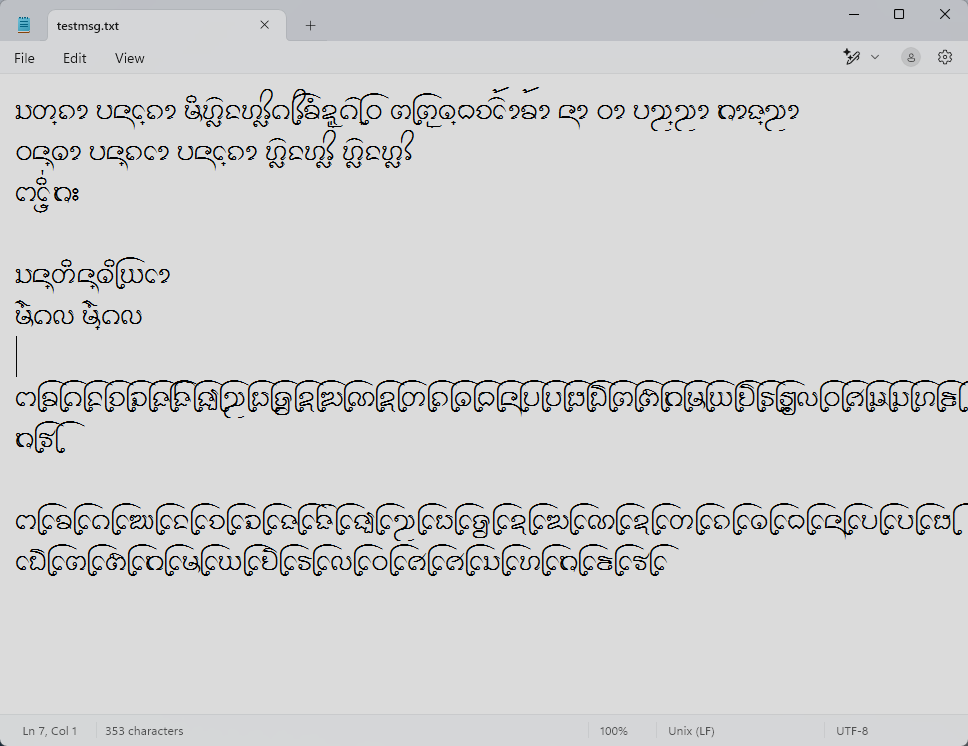
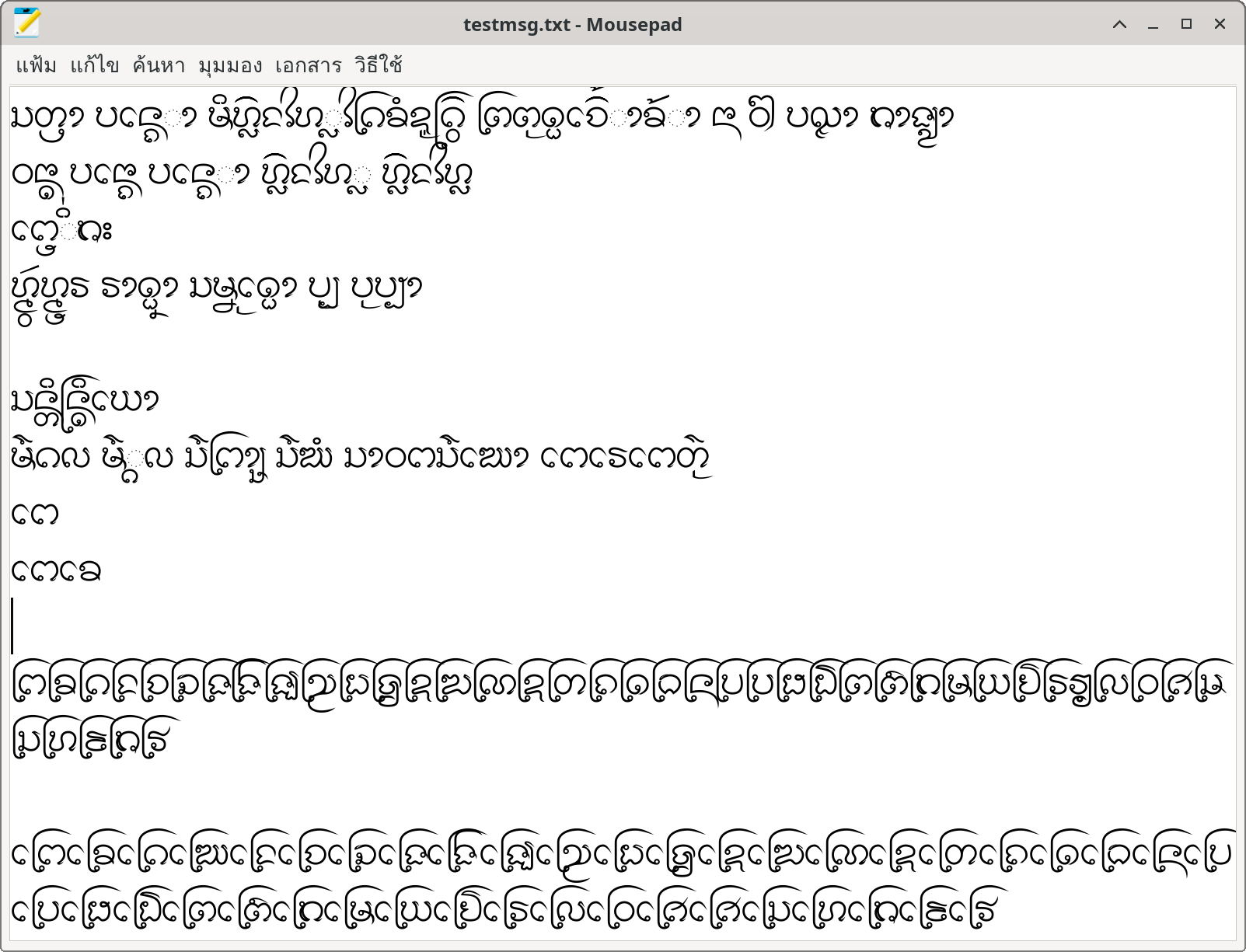
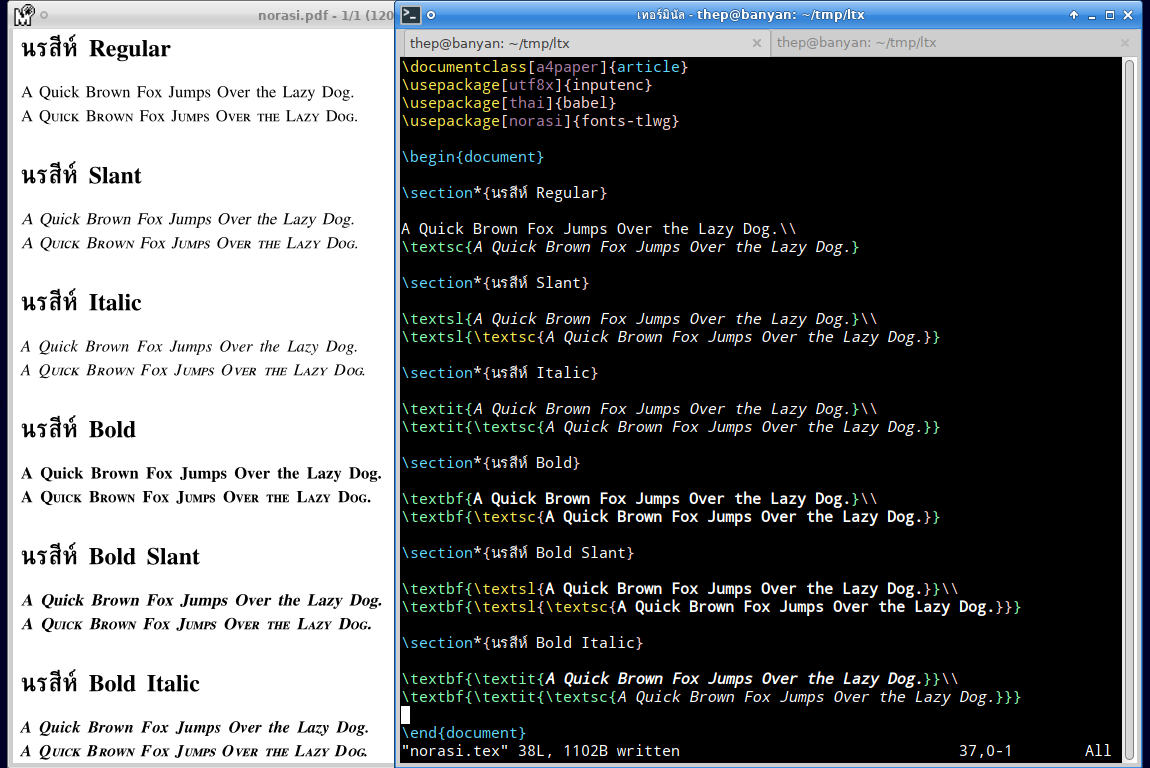
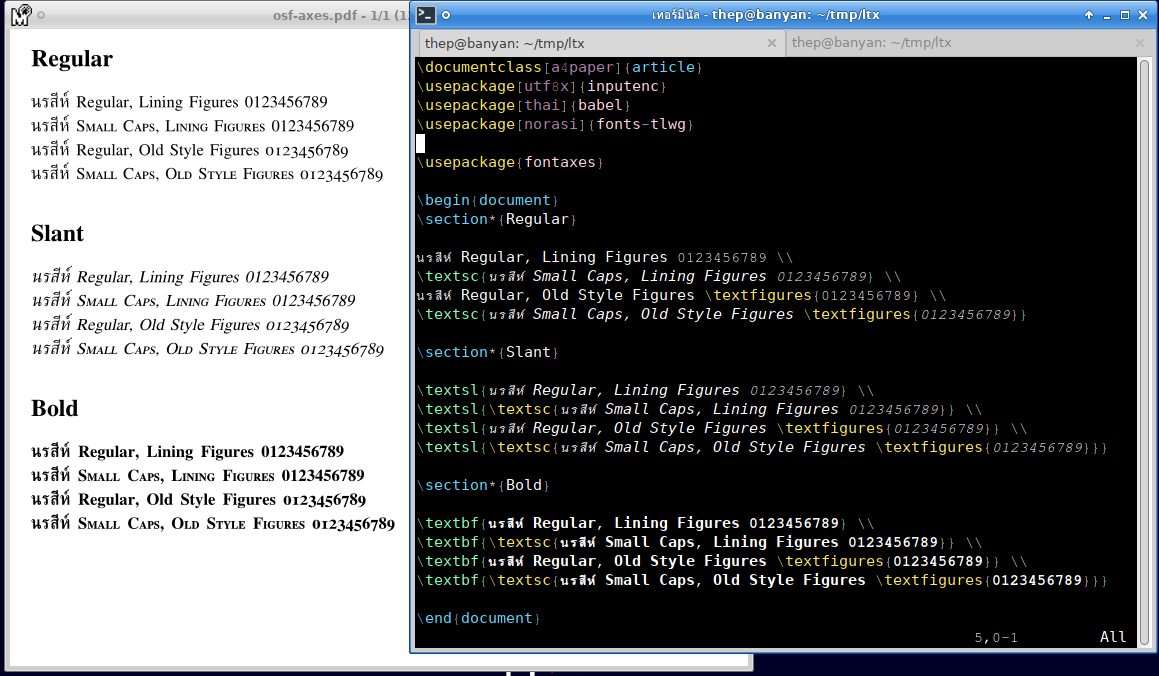
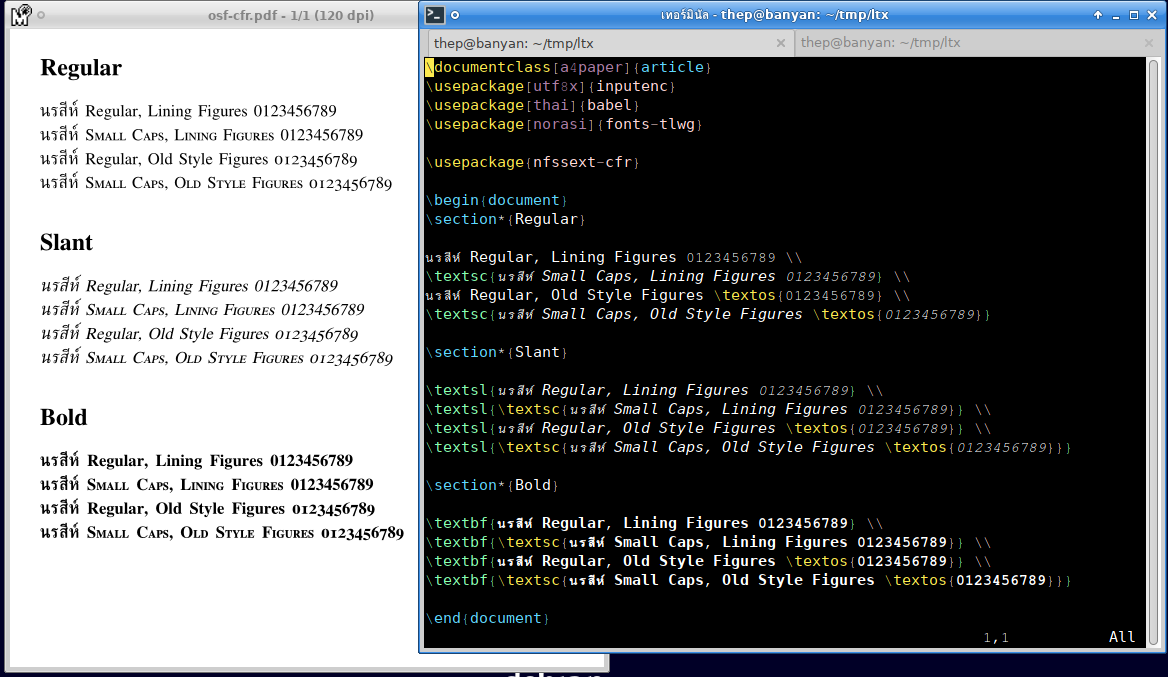
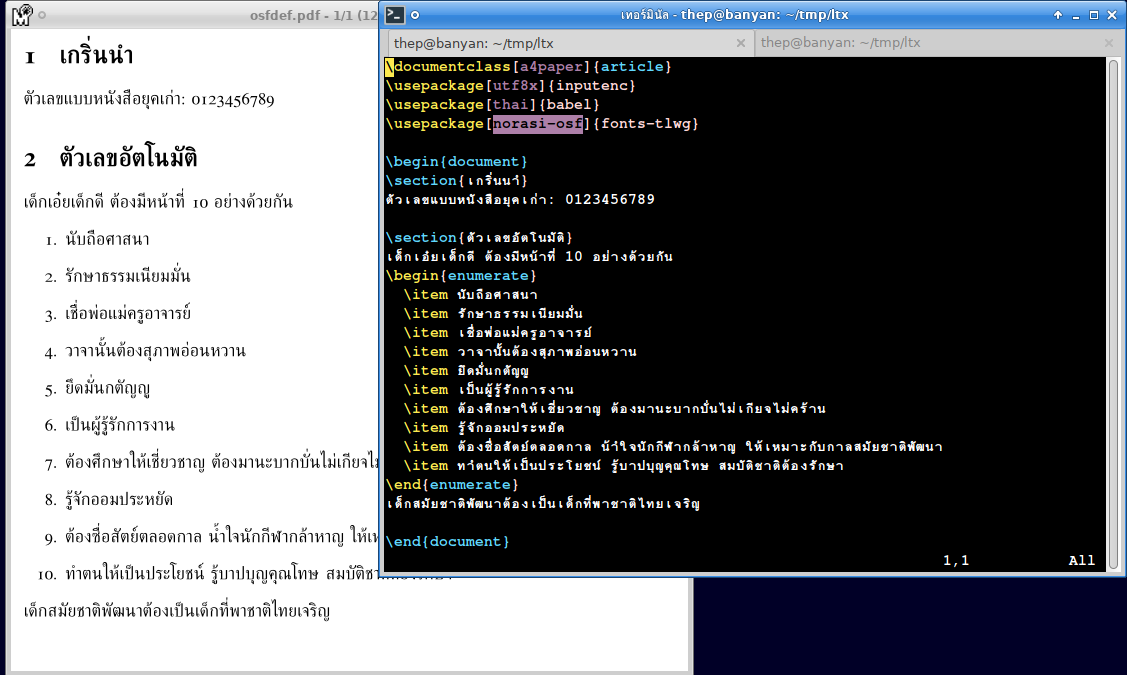
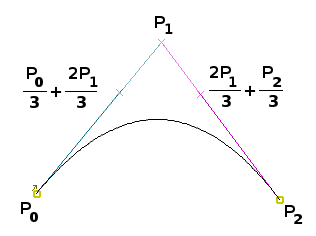
To USE or Not to USE for Lao Tham
จาก blog ที่แล้ว ผมได้เล่าถึงการรองรับอักษรธรรมในปัจจุบันที่ text shaping engine ต่างๆ หันมาใช้ Universal Shaping Engine (USE) ตามข้อกำหนดของไมโครซอฟท์ โดย USE เองเป็น engine ครอบจักรวาลที่มีการจัดการภายในตามคุณสมบัติของอักขระ Unicode เช่น การสลับสระหน้ากับพยัญชนะต้นสำหรับอักษรตระกูลพราหมี และเรียกใช้ OpenType feature ต่างๆ ในฟอนต์ตามลำดับที่กำหนดไว้
และการจัดการภายในของ USE ก็ทำให้มีข้อเสนอที่จะปรับโครงสร้างการลงรหัสข้อความอักษรธรรมเพื่อให้ทำงานกับ USE ได้ แต่มันก็ยังไม่เข้าที่เข้าทางนัก จึงเกิดแนวคิดที่จะหลบเลี่ยง USE แล้วทำทุกอย่างเองในฟอนต์ แต่ไปติดปัญหาที่ MS Word ที่ไม่ยอมให้หลบได้ง่ายๆ ทำให้เราอยู่บนทางแยกที่ต้องเลือกว่าจะใช้ USE ที่ยังไม่เข้าที่ หรือจะเลี่ยง USE ไปทำทุกอย่างเองโดยทิ้ง MS Word ไว้ข้างหลัง
blog นี้ก็จะวิเคราะห์ต่อ ว่าทางเลือกแต่ละทางมีข้อดีข้อเสียอย่างไร
Encoding แบบใหม่
ตามข้อเสนอในเอกสาร Structuring Tai Tham Unicode เมื่อตัดรายละเอียดที่อักษรธรรมลาว/อีสานไม่ใช้ออกไป ก็พอจะสรุปลำดับอักขระในข้อความได้เป็น:
S ::= CC (Vs | Vf)?
โดยที่ CC คือ consonant cluster พร้อมสระหน้า/ล่าง/บน วรรณยุกต์ สระหรือตัวสะกดปิดท้าย
CC ::= C M? V? T? F? C ::= [<ก>-<ฮ><อิลอย>-<โอลอย><แล><ส_สองห้อง><ตัวเลข>] | <ห><SAKOT>[<ก>-<ม>] M ::= <ระวง>? <ล_ล่าง>? (<SAKOT><ว>)? (<SAKOT><ย>)? V ::= Vp? Vb? Va? Vp ::= [<เอ>-<ไม้ม้วน>] // สระหน้า Vb ::= [<อุ>-<อู><ออ_ล่าง>] // สระล่าง Va ::= [<อิ>-<อือ><ไม้กง><ไม้เก๋าห่อนึ่ง>][<ไม้ซัด><ไม้กั๋ง>]? // สระบน T ::= [<ไม้เอก>-<ไม้โท>] F ::= Fs? [<ละทั้งหลาย><ไม้กั๋งไหล><ง_บน><ม_ล่าง><บ_ล่าง><ส_ล่าง><ไม้กั๋ง>]? (<SAKOT> S)? Fs ::= [<อ><ส_สองห้อง><ออย>] | <SAKOT>[<ก>-<ฬ>] // อ ของสระเอือ หรือ ตัวสะกด
สังเกตว่ามี recursion ใน F เพื่อแทนลูกโซ่ของพยางค์ในคำบาลีด้วย
ต่อจาก CC ก็จะตามด้วยสระกินที่ (spacing vowels) ซึ่งแบ่งเป็นสระมีตัวสะกด (Vs) และสระไม่มีตัวสะกด (Vf)
สำหรับสระมีตัวสะกด Vs คือสระอาหรือสระอำ (สระอำในอักษรธรรมไม่ได้มีรหัสอักขระเฉพาะเหมือนอักษรไทย แต่แทนด้วยสระอาตามด้วยไม้กั๋ง (นิคหิต) ความจริงอาจนับไม้กั๋งเป็นตัวสะกดในสระอำก็ได้ แต่กฎนี้พยายามจัดการสระอากับสระอำไปด้วยกัน กลายเป็นว่าสระอำก็ยังมีตัวสะกดได้อีก) พร้อมตัวสะกด Fs (ถ้ามี)
Vs ::= AV Fs? AV ::= [<อา><อาสูง>] <ไม้กั๋ง>? // สระอา สระอำ
ส่วนสระไม่มีตัวสะกด Vf ในตัวเนื้อหาของร่างฯ ได้บรรยายถึงสระเอาะและสระเอือะ แต่ในสรุปส่วนท้ายดูจะลืมสระเอาะไป และยังจัดการ อ ของสระเอือะซ้ำซ้อนกับใน Fs อีก
Vf ::= <อ>? <อะ> // วิสรรชนีย์ของสระเอือะ
Encoding แบบ USE
แม้ encoding แบบใหม่ที่เสนอมีจุดมุ่งหมายเพื่อให้วาดแสดงด้วย USE แต่เมื่อลองใช้กับ USE จริงกลับยังมี dotted circle เกิดขึ้นในหลายกรณี ซึ่งจากการทดลองก็พอจะสังเกตลักษณะของ USE ที่ต่างจากโครงสร้างที่เสนอในร่างดังนี้:
- ลำดับสระใน
Vสระบนมาก่อนสระล่าง ไม่ใช่ตามหลังสระล่างอย่างในร่างฯ ดังนั้นจึงอาจปรับกฎเป็น:V ::= Vp? Va? Vb?
- วรรณยุกต์อยู่หน้าสระกินที่ไม่ได้ แต่ตามหลังได้ และต้องอยู่ก่อนตัวสะกด ดูเหมือน USE จะนับ
Vsเป็นส่วนหนึ่งของV:V ::= Vp? Va? Vb? Vs?
ซึ่งถ้าเป็นเช่นนั้น ก็หมายความว่า USE ก็ยังต้องการการ reorder ให้วรรณยุกต์ไปอยู่ในตำแหน่งก่อนหน้าสระกินที่เพื่อให้สามารถซ้อนบนพยัญชนะได้ด้วย มันจะกลายเป็นความซับซ้อนเกินจำเป็นน่ะสิ
หลักการสำหรับการป้อนข้อความ
สมมติว่าเราใช้ encoding แบบ USE เราจะมีหลักในใจอย่างไร? เราจะใช้ลำดับการพิมพ์แบบที่เราเคยใช้กับอักษรไทยไม่ได้อีกแล้ว เพราะมันคือการ encode แบบกึ่ง visual ไม่ว่าเขาจะยืนยันที่จะเรียกว่า logical order
ยังไงก็ตาม แต่ลำดับการ encode นี้จะไม่ตรงกับลำดับการสะกดคำเสมอไป มันเน้นให้เรียงพิมพ์ได้เป็นหลัก! โดยมีลำดับแบบที่เรียกว่า logical order
มาหลอกให้งงเล่น
หลักการคือ
- ละทิ้งลำดับการสะกดในใจไว้ก่อน พิจารณารูปร่างของข้อความที่ต้องการ แล้ว encode ตามกฎในข้อถัดๆ ไป
- ผสมตัวห้อย ตัวเฟื้อง หรือระวง กับพยัญชนะต้นก่อน โดยมากเป็นตัวควบกล้ำ
- ตามด้วยสระ โดยถ้ามีสระหลายตัว ให้วางสระตามลำดับ หน้า, บน, ล่าง, ขวา
- ตามด้วยวรรณยุกต์
- ตามด้วยตัวสะกด ซึ่งอาจเป็นตัวห้อย, ตัวเฟื้อง, ไม้กั๋ง, ง สะกดบน, หรือไม้กั๋งไหล
- ถ้ามีการเชื่อมพยางค์เป็นลูกโซ่แบบบาลี ก็นับตัวสะกดเป็นพยัญชนะต้นของพยางค์ถัดไปแล้วใส่สระตามได้เลย
ความไม่ปกติของลำดับ
หลักการที่ว่าไปก็ดูปกติดีนี่? แต่ความซับซ้อนของอักษรธรรมทำให้มันไม่ตรงไปตรงมาอย่างนั้น ต่อไปนี้คือกรณีต่างๆ ที่ฝืนความรู้สึก อย่างน้อยก็ในระยะแรก
การสะกดแม่กกด้วยไม้ซัด
ไม้ซัดถือว่าเป็นสระบน (Va) ในกฎ ซึ่ง encoding ในร่างฯ สามารถตามหลังสระล่าง (Vb) ได้ แต่ตาม encoding ของ USE ต้องมาก่อนสระล่าง ดังนั้น เมื่อไม้ซัดทำหน้าที่เป็นตัวสะกดแม่กก จึงต้องใช้ลำดับที่ตัวสะกดมาก่อนสระ ไม่ใช่สระมาก่อนตัวสะกด

แต่ก็จะมีกรณีที่ไม่สามารถ encode ได้ ไม่ว่าจะตามร่างฯ หรือตาม USE คือเมื่อเป็นตัวสะกดของสระอา

อาจจะยกเว้นคำว่า นาค
ที่สามารถซ่อนลำดับไว้ภายใต้รูปเขียนพิเศษได้

เมื่อมีตัวห้อย/ตัวเฟื้องหรือสระระหว่าง cluster
การเขียนอักษรธรรมในหลายกรณีมีการใช้ตัวห้อย/ตัวเฟื้องเป็นพยัญชนะต้นของพยางค์ถัดไป แทนที่จะใช้ตัวเต็ม ซึ่งในกรณีเหล่านี้ ถ้าวางตัวห้อย/ตัวเฟื้องในตำแหน่งของตัวสะกด ก็จะไม่สามารถวางสระต่อได้อีก เพราะดูเหมือน USE ไม่ได้รองรับ recursion ใน F ตามกฎในร่างฯ และเมื่อแจงต่อไป CC ของพยางค์ถัดไปก็ขาดพยัญชนะต้นตัวเต็ม (C) มาขึ้นต้น CC แต่ถ้า encode โดยเลี่ยงให้ตัวห้อย/ตัวเฟื้องดังกล่าวเป็นส่วนหนึ่งของ CC ของพยางค์ก่อนหน้าก็จะสามารถวางสระต่อได้ แต่ลำดับก็จะดูขัดสามัญสำนึกสักหน่อย
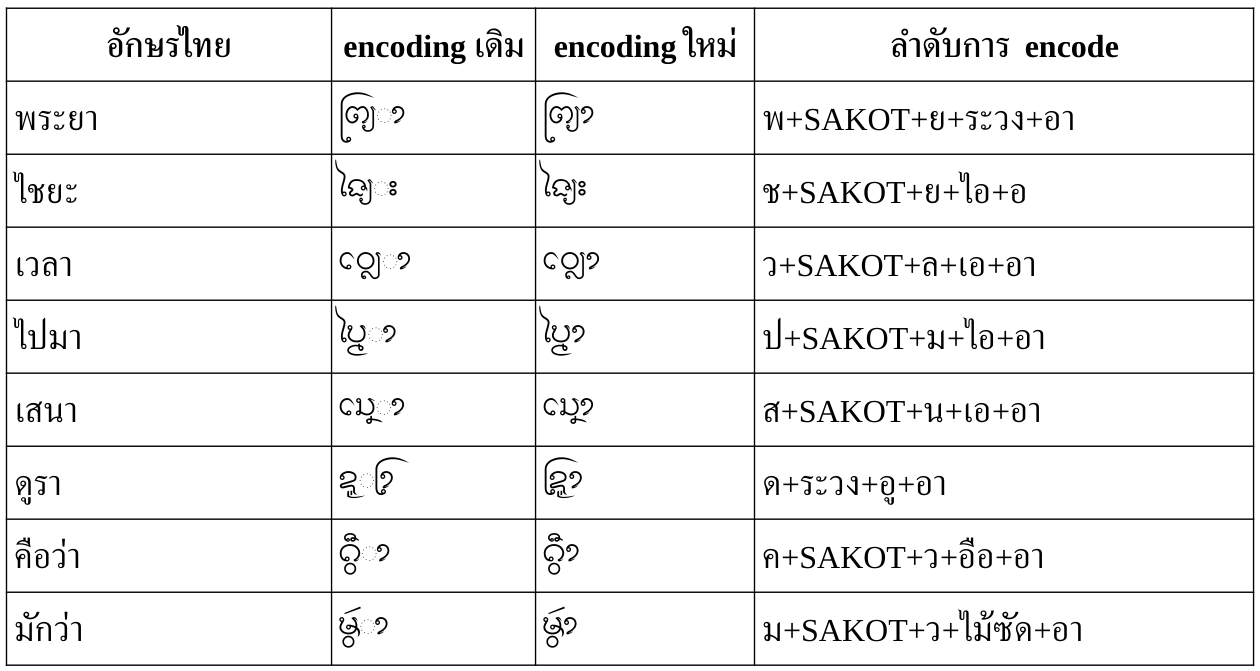
แต่ในบางกรณีก็ไม่เอื้อให้ทำเช่นนั้น เช่น เมื่อมีสระมาคั่นในแบบที่ไม่สามารถสลับลำดับได้

ในคำย่อที่มีการยืมพยัญชนะต้น
บ่อยครั้งที่อักษรธรรมมีการใช้รูปเขียนย่อในลักษณะที่ใช้พยัญชนะต้นตัวเดียวซ้ำในพยางค์มากกว่าหนึ่งพยางค์ ในจำนวนนั้น บางคำอาจสามารถยังจัดลำดับอักขระจนเข้ากับกฎเกณฑ์ของ USE ได้ แม้จะดูเหมือนการเปลี่ยนหน้าที่อักขระ เช่น เปลี่ยนตัวสะกดมาเป็นตัวควบ หรืออาจมีการสลับลำดับสระของพยางค์ต่างๆ
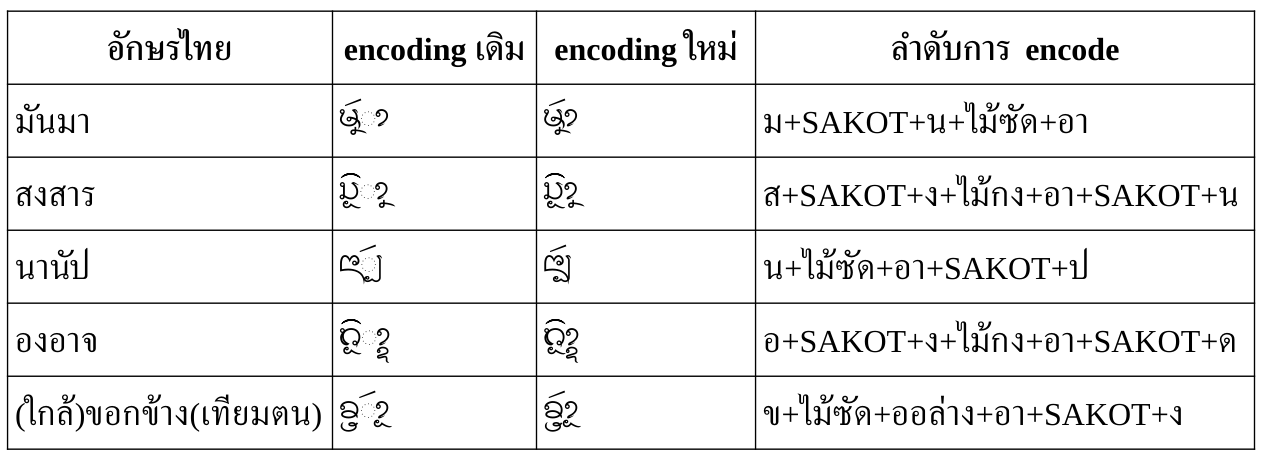
แต่บางกรณีก็ไม่สามารถจัดลำดับให้เข้าเกณฑ์ได้

วิธีหลบเลี่ยง?
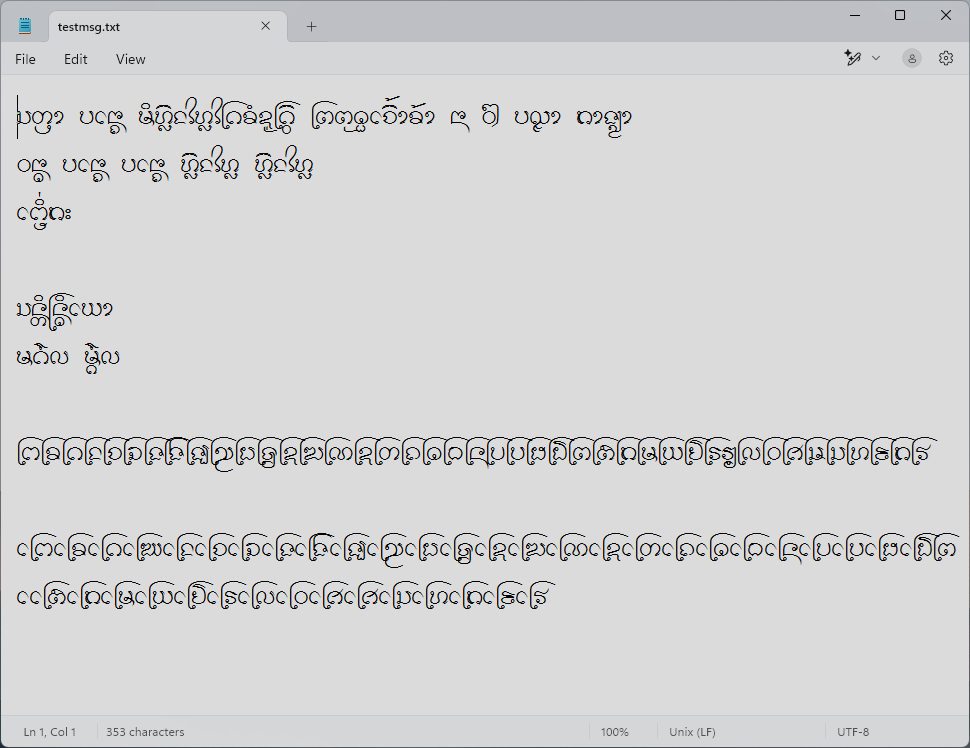
อย่างไรก็ดี ปัญหาทั้งหมดนี้สามารถหลบเลี่ยงได้ โดยลบ glyph DOTTED CIRCLE (uni25CC) ออกจากฟอนต์เสีย แล้ว USE ก็จะไม่แสดง dotted circle อีกเลย!

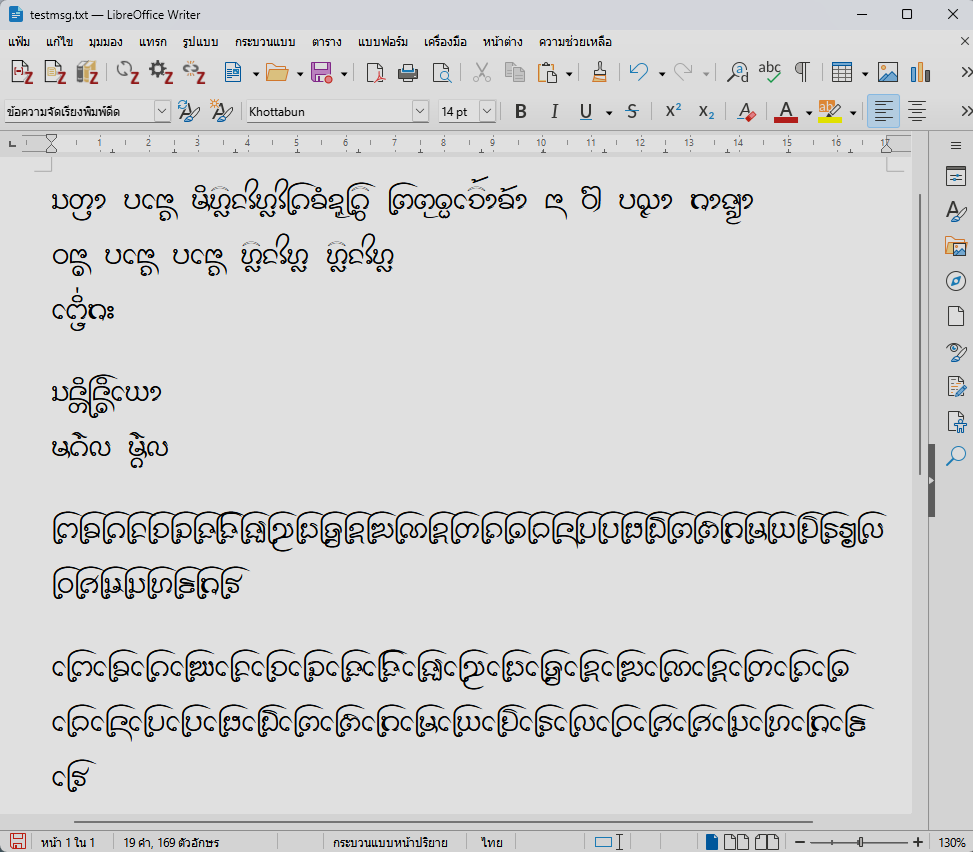
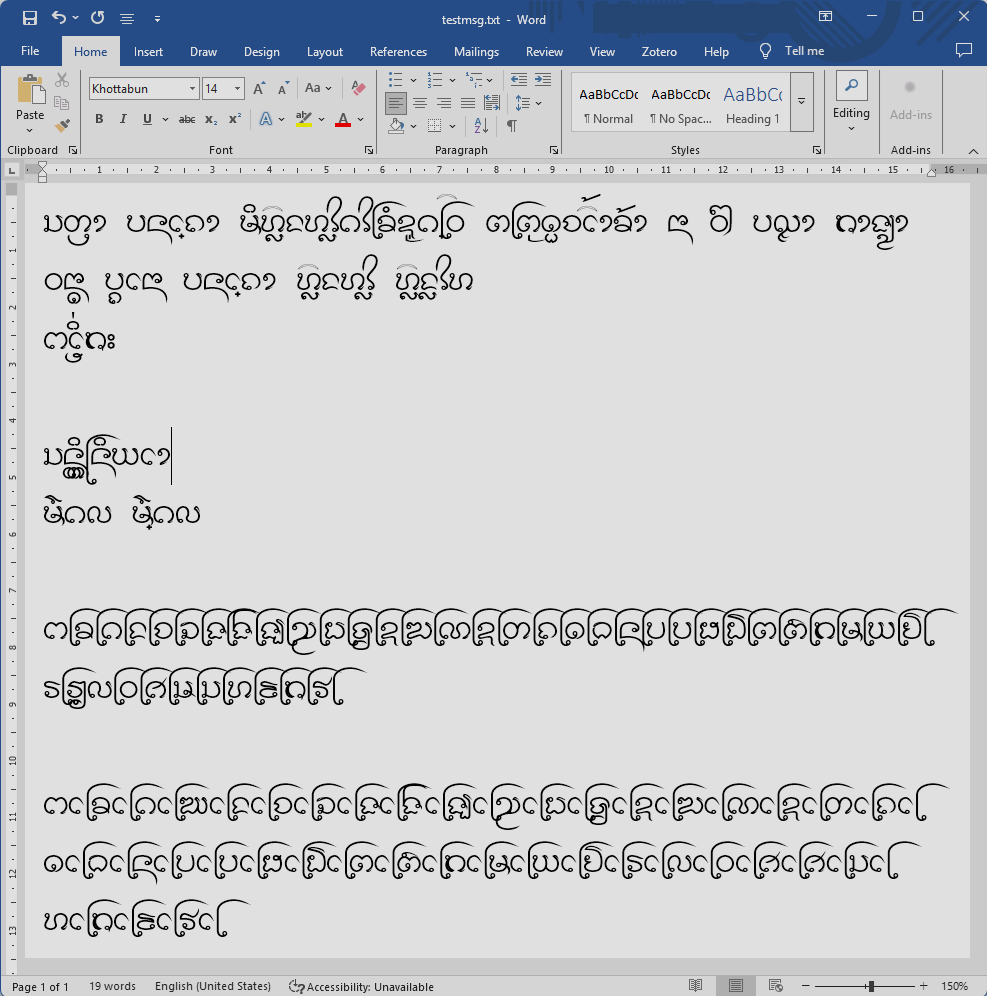
ที่กล่าวมาทั้งหมดนี้คือการทดสอบกับแอปที่ใช้ Harfbuzz แต่สุดท้าย เมื่อนำไปทดสอบกับ MS Word ปรากฏว่ามันก็ยังไม่ยอมง่ายๆ อยู่ดี โดยปัญหาหลักที่พบมีสองข้อ ข้อแรกคือกฎของตัวห้อย/ตัวเฟื้องจะไม่ทำงานถ้าไม่ได้ตามหลังพยัญชนะต้นทันที เช่น เป็นตัวสะกดของสระอา หรือมีสระอื่นมาคั่นกลาง กล่าวคือ
ดูจะถูกเรียกเฉพาะในตำแหน่งพยัญชนะซ้อนกันเท่านั้น ไม่เรียกในตำแหน่งตัวสะกด และอีกข้อหนึ่งคือกฎ ligature สำหรับ blwfนา
ไม่ทำงานเมื่อมีอักขระซ้อนบน/ล่าง
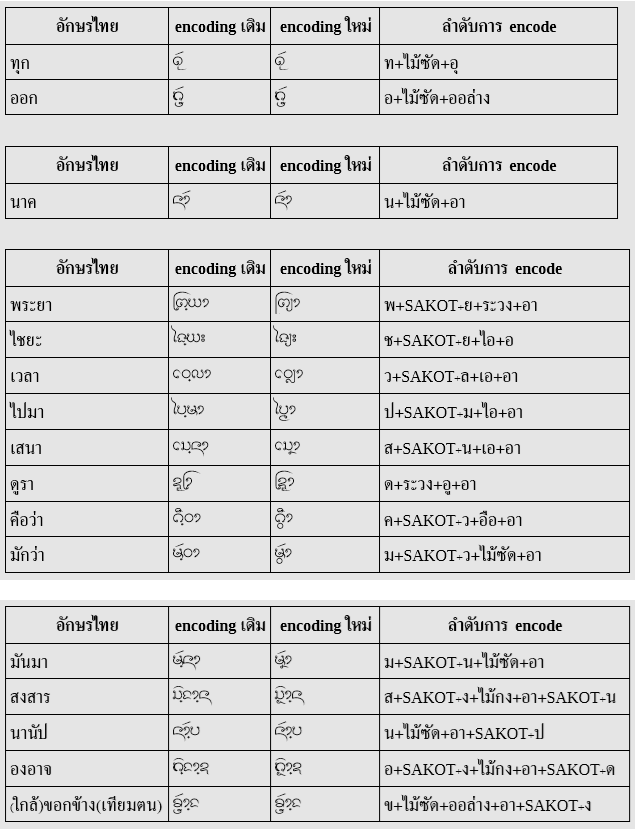

สรุป
ประเด็นต่างๆ ที่พบ พอจะสรุปได้ตังตาราง
| ประเด็น | ใช้ USE | เลี่ยง USE |
|---|---|---|
| วิธีการ |
|
|
| การ encode ข้อความ | กึ่ง visual (ขัดสามัญสำนึกนิดหน่อย) | ตามหลักการสะกดคำ |
| แอปที่รองรับ | Harfbuzz app*, MS Word (บางส่วน) | Harfbuzz app*, Notepad |
| อาการเมื่อไม่รองรับ |
|
|
*Harfbuzz app เช่น LibreOffice, Firefox, Gedit, Mousepad ฯลฯ
จึงพอสรุปได้ว่ายังมีความแตกต่างระหว่างข้อกำหนดในร่างฯ กับสิ่งที่ USE รองรับจริง ทำให้ไม่ว่าจะพยายามอย่างไรก็จะมีข้อบกพร่องเกิดขึ้นเสมอ และแอปที่มีปัญหาเสมอๆ ก็คือ MS Word
หากเลือกใช้ข้อกำหนด USE ทุกแอปที่รองรับ USE ก็จะได้การรองรับแบบ เกือบๆ
ครบถ้วน (โดย MS Word จะมีปัญหามากกว่าเพื่อนสักหน่อย) โดยแลกกับลำดับการ encode ที่ผิดธรรมชาติของผู้ใช้ ซึ่งเป็นการแลกที่ผมคิดว่าไม่คุ้ม เพราะจะมีผลให้เกิดเอกสารที่ encode แปลกๆ เกิดขึ้นในระหว่างที่ USE ยังไม่พร้อม แถมสิ่งที่ได้คืนมาก็ยังไม่ใช่สิ่งที่สมบูรณ์เสียด้วย
ในขณะที่หากเลือกหลีกเลี่ยง USE แอปส่วนใหญ่ยกเว้น MS Word ก็จะสามารถจัดแสดงอักษรธรรมได้สมบูรณ์ (ดังกล่าวไว้ใน blog ที่แล้ว) โดยที่ผู้ใช้ก็ยังคงใช้ encoding แบบเก่าได้เช่นเดิม และเมื่อไรที่ USE พร้อม ก็เพียงแปลง encoding ไปเป็นแบบใหม่ (ซึ่งอาจจะอัตโนมัติหรือ manual ก็ค่อยว่ากัน) โดยไม่ต้องมี encoding ชั่วคราวของ USE มาแทรกกลางเป็นชนิดที่สามให้เกิดความสับสนเพิ่ม โดยแลกกับการทิ้ง MS Word ที่ยังไงก็ไม่สมบูรณ์อยู่แล้ว และแนะนำให้ผู้ใช้อักษรธรรมใช้ LibreOffice หรือ Notepad (ซึ่งเป็นผลพลอยได้) ในการเตรียมเอกสารแทน ส่วนเว็บเบราว์เซอร์นั้นไม่เป็นปัญหา เพราะเบราว์เซอร์ส่วนใหญ่ก็ใช้ Harfbuzz เป็นฐานกันอยู่แล้ว การรองรับก็จะเหมือนๆ กับใน LibreOffice นั่นแล
ด้วยเหตุนี้ ผมจึงเลือกที่จะสร้างฟอนต์อักษรธรรมที่ หลีกเลี่ยง USE ต่อไป จนกว่า USE จะพร้อมจริงๆ
ป้ายกำกับ: tham, typography, unicode
บันทึกโดย Thep ณ
17:04
0 ความเห็น
![]()