Fonts-TLWG 0.6.3 ออกแล้ว เมื่ออาทิตย์ที่แล้ว แต่เพิ่งจะได้เขียน blog บันทึกหลังจากที่เตรียมแพกเกจเพื่ออัปโหลดในที่ต่าง ๆ เสร็จ คือที่ Debian และ CTAN
รุ่นนี้เป็นรุ่นแรกที่ ออกรุ่นจาก GitHub หลังจากที่ ประกาศย้าย repository ของ TLWG ไปที่ GitHub เมื่อเดือนที่แล้ว แต่ยังคงใช้ linux.thai.net เป็นที่ประกาศหลักตามเดิม เพื่อความต่อเนื่องกับรุ่นก่อน ๆ
ความเปลี่ยนแปลงหลักที่เกิดขึ้นในรุ่นนี้ คือการเปลี่ยนให้ฟอนต์ Loma เป็นฟอนต์ UI หลักแทน Waree อันเนื่องมาจาก รายงานบั๊กของพี่สัมพันธ์ พร้อม follow-up ว่าฟอนต์ Waree นั้นตัวสูงเกินไปจนถูกขริบในบางเว็บ เช่น Facebook แต่ Loma นั้นเตี้ยพอที่จะเล็ดรอดมาได้ (เหตุผลก็คือ Waree นั้นออกแบบเพื่อเตรียมเพิ่มอักษรไทยให้กับฟอนต์ DejaVu Sans จึงมี glyph ละตินของ DejaVu Sans ซึ่งตัวสูงอยู่แล้วเป็นตัวตั้ง ส่วน Loma นั้น เข้าใจว่าออกแบบโดยอิสระของตัวเอง) หลังจากทดสอบและฟังความเห็นของหลาย ๆ ท่านที่มาคอมเมนต์ ก็เห็นว่าควรเลื่อนอันดับของฟอนต์ Loma ขึ้นมาสูงกว่า Waree ในการเลือกฟอนต์ sans-serif ของ fontconfig
ในการเลื่อนขั้นนั้น ตามหลักแล้วควรจะทำได้ง่าย ๆ ด้วยการเปลี่ยนลำดับแฟ้ม config ของ fontconfig ให้ Loma ขึ้นก่อน Waree เช่น เปลี่ยนชื่อแฟ้ม /etc/fonts/conf.d/64-12-tlwg-loma.conf ในรุ่น 0.6.2 ให้เป็น 64-10-tlwg-loma.conf แต่ทำแค่นั้นไม่ได้ช่วยให้ Loma มาก่อน Waree ได้ เพราะยังมีกฎชุด synthetic อีกชุดหนึ่งเข้ามามีส่วนด้วย ดังผลลัพธ์หลังเปลี่ยนชื่อแฟ้มดังกล่าว ก็ยังคง match sans-serif ได้ Waree เช่นเดิม (ในรุ่น 0.6.2):
$ cd /etc/fonts/conf.d
$ sudo mv 64-12-tlwg-loma.conf 64-10-tlwg-loma.conf
$ fc-match sans-serif
Waree.otf: "Waree" "Regular"
สาเหตุคือฟอนต์ Waree มีการจำลองตัวเองเพื่อทดแทนฟอนต์ Tahoma ด้วยการห้อยชื่อตัวเองในลำดับต่อจาก Tahoma (ในไฟล์ 89-tlwg-waree-synthetic.conf) แต่ด้วยความที่ Tahoma ได้ถูกกำหนดให้เป็น preferred font ตัวหนึ่งของละติน (ในไฟล์ 60-latin.conf) ซึ่งมาก่อนภาษาอื่น ๆ การจำลอง Tahoma ของ Waree จึงทำให้ Waree กลายเป็นฟอนต์ละตินตัวหนึ่งที่มาก่อนภาษาอื่น ๆ ไปด้วย!
รายละเอียดทางเทคนิคของการตรวจสอบ ผู้ที่สนใจสามารถอ่านได้ที่ส่วนท้ายของ blog
ฉะนั้น การจะเลื่อนขั้น Loma ขึ้น จึงติดที่กฎชุด synthetic ของ Waree นี้
แล้วกฎ synthetic นี้มาจากไหน? มันเริ่มมาจากแนวคิดการจำลองฟอนต์ที่ผู้ใช้นิยมใช้ในเอกสารต่าง ๆ บนวินโดวส์ด้วยฟอนต์ที่มีในชุด Fonts-TLWG เช่น จำลอง Angsana ด้วย Kinnari, จำลอง Browallia ด้วย Garuda ฯลฯ ดังมีบันทึกไว้ใน blog เก่าเมื่อปี 2550 ซึ่งฟอนต์ต่าง ๆ ก็มีเค้าหน้าตาให้จำลองกันได้ จนกระทั่งมาเจอกรณีการใช้ฟอนต์ MS Sans Serif และ Tahoma ในเว็บ จึงได้พยายามทดแทนด้วยฟอนต์ Loma และ Waree ตามลำดับ ดังอ้างถึงใน blog เก่าเมื่อปี 2552 โดยที่ทั้งสองฟอนต์นี้ไม่ได้มีเค้าของฟอนต์ที่จำลองเลย เพียงแต่ต้องการอุดช่องว่างของการแสดงหน้าเว็บเท่านั้น
กฎนี้เคยถูกรายงานว่าสร้างปัญหาให้กับภาษาอื่น เพราะ Waree จะโผล่มาแทน Tahoma ทั้ง ๆ ที่ตัวใหญ่กว่า Tahoma (LP #434054) ทำให้เคยตัดกฏนี้ออกไปชั่วระยะหนึ่ง แต่ก็เพิ่มกลับเข้ามาพร้อมกับการตรวจสอบภาษาเพิ่มเติมเพื่อให้ apply กับภาษาไทยเท่านั้น (LP #539008) ดังบันทึกใน thaifonts-scalable 0.4.14 แต่ในเมื่อมันมารบกวนการจัดอันดับฟอนต์ sans-serif ไทยทั้งระบบ ก็เห็นควรว่าควรตัดกฎ synthetic นี้ออก แล้วปล่อยให้ฟอนต์ sans-serif ที่ได้อันดับสูงสุดมาอุด Tahoma เอา
เมื่อตัดกฎ synthetic ออก ฟอนต์ Loma ก็ได้อันดับสูงกว่า Waree แล้ว
อีกประเด็นหนึ่งที่พบระหว่างทดลองใช้ Loma เป็นฟอนต์ UI หลัก นอกเหนือจากขนาดที่เล็กลงถนัดตาที่ใช้เวลาสักพักก็จะชินแล้ว ก็มีเรื่องความกว้างของอักขระเว้นวรรค (space) ที่กว้างเกินพอดี และเมื่อเทียบกับฟอนต์ทั่วไปก็ยิ่งยืนยันได้ จึงได้ปรับลดความกว้างของอักขระเว้นวรรคให้แคบลง ซึ่งก็ทำให้ย่อหน้าภาษาอังกฤษไม่ดูโหรงเหรงจนเกินไป
ก่อนปรับ:
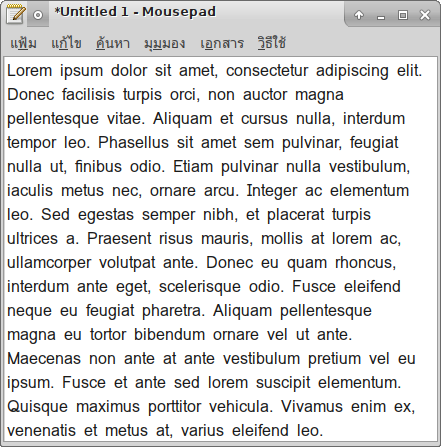
หลังปรับ:
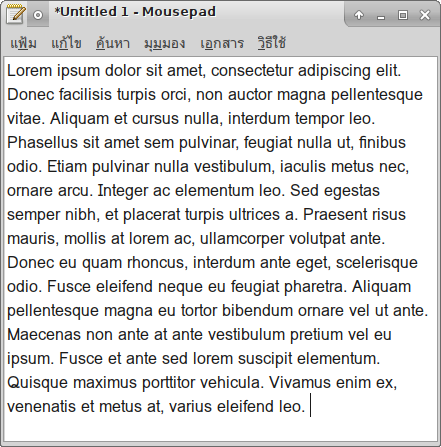
ทั้งหมดนั้น เสิร์ฟถึงคุณแล้วในรุ่น 0.6.3 ครับ!
ต่อไปนี้เป็นวิธีตรวจสอบการ apply กฎของ fontconfig ด้วยตัวเอง ซึ่งทำให้เห็นว่ากฎ synthetic ใน 0.6.2 ทำให้ Waree ล้ำหน้าฟอนต์ไทยอื่น ๆ ได้อย่างไร
วิธีตรวจสอบตามที่ เอกสาร fontconfig ได้อธิบายไว้ คือกำหนดตัวแปร environment FC_DEBUG โดยในที่นี้เราสนใจการ edit match pattern ในกฎต่าง ๆ ก็กำหนดค่าเป็น 4 แล้วเรียก fc-match ดังนี้:
$ FC_DEBUG=4 fc-match sans-serif
มันจะพ่นข้อความแสดงการ edit match pattern ในแต่ละขั้นออกมายืดยาว ก็อาจจะ redirect ลงแฟ้มแล้วมาตรวจสอบดู ก็จะพบขั้นตอนที่น่าสนใจคือ:
...
FcConfigSubstitute test pattern any family Equal(ignore blanks) "sans-serif"
Substitute Edit family Prepend "Bitstream Vera Sans" Comma "DejaVu Sans" Comma "
Verdana" Comma "Arial" Comma "Albany AMT" Comma "Luxi Sans" Comma "Nimbus Sans L
" Comma "Helvetica" Comma "Lucida Sans Unicode" Comma "BPG Glaho International"
Comma "Tahoma"
Prepend list before "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w)
[marker] "sans-serif"(s) "sans-serif"(w)
Prepend list after "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w) "
Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w)
"Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) "sans-serif"(s) "sans-serif"(w)
...
กฎนี้มาจาก 60-latin.conf ของ fontconfig เอง ที่เพิ่ม prefer list ของ sans-serif โดยมี Tahoma พ่วงอยู่ด้วย
จากนั้น ก็มีการ edit match pattern ต่อ ๆ มา จนมาถึงตรงนี้:
...
FcConfigSubstitute test pattern any family Equal(ignore blanks) "sans-serif"
Substitute Edit family Prepend "Loma"
Prepend list before "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w)
"Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w
) "Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) [marker] "sans-serif"(s) "sans-serif"(w)
Prepend list after "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w) "
Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w)
"Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) "Loma"(w) "sans-serif"(s) "sans-serif"(w)
...
FcConfigSubstitute test pattern any family Equal(ignore blanks) "sans-serif"
Substitute Edit family Prepend "Waree"
Prepend list before "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w)
"Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w
) "Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) "Loma"(w) [marker] "sans-serif"(s) "sans-se
rif"(w)
Prepend list after "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w) "
Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w)
"Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) "Loma"(w) "Waree"(w) "sans-serif"(s) "sans-s
erif"(w)
...
ซึ่งก็ดูเรียบร้อยดี Loma น่าจะ match ก่อน Waree แล้ว จนกระทั่งมาถึงตรงนี้:
...
FcConfigSubstitute test pattern any lang Contains "th"
FcConfigSubstitute test pattern any family Equal "Tahoma"
Substitute Edit family Append "Waree"
Append list before "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w) "
Bitstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w)
"Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG
Glaho International"(w) "Tahoma"(w) [marker] "Loma"(w) "Waree"(w) "Garuda"(w) "U
mpush"(w) "Laksaman"(w) "Meera"(w) "Khmer OS"(w) "Nachlieli"(w) "Lucida Sans Uni
code"(w) "Yudit Unicode"(w) "Kerkis"(w) "ArmNet Helvetica"(w) "Artsounk"(w) "BPG
UTF8 M"(w) "Waree"(w) "Loma"(w) "Garuda"(w) "Umpush"(w) "Saysettha Unicode"(w)
"JG Lao Old Arial"(w) "GF Zemen Unicode"(w) "Pigiarniq"(w) "B Davat"(w) "B Comps
et"(w) "Kacst-Qr"(w) "Urdu Nastaliq Unicode"(w) "Raghindi"(w) "Mukti Narrow"(w)
"padmaa"(w) "Hapax Berbère"(w) "MS Gothic"(w) "UmePlus P Gothic"(w) "SimSun"(w)
"PMingLiu"(w) "WenQuanYi Zen Hei"(w) "WenQuanYi Bitmap Song"(w) "AR PL ShanHeiSu
n Uni"(w) "AR PL New Sung"(w) "MgOpen Moderna"(w) "MgOpen Modata"(w) "MgOpen Cos
metica"(w) "VL Gothic"(w) "IPAMonaGothic"(w) "IPAGothic"(w) "Sazanami Gothic"(w)
"Kochi Gothic"(w) "AR PL KaitiM GB"(w) "AR PL KaitiM Big5"(w) "AR PL ShanHeiSun
Uni"(w) "AR PL SungtiL GB"(w) "AR PL Mingti2L Big5"(w) "MS ゴシック"(w) "ZYSo
ng18030"(w) "NanumGothic"(w) "UnDotum"(w) "Baekmuk Dotum"(w) "Baekmuk Gulim"(w)
"KacstQura"(w) "Lohit Bengali"(w) "Lohit Gujarati"(w) "Lohit Hindi"(w) "Lohit Ma
rathi"(w) "Lohit Maithili"(w) "Lohit Kashmiri"(w) "Lohit Konkani"(w) "Lohit Nepa
li"(w) "Lohit Sindhi"(w) "Lohit Punjabi"(w) "Lohit Tamil"(w) "Meera"(w) "Lohit M
alayalam"(w) "Lohit Kannada"(w) "Lohit Telugu"(w) "Lohit Oriya"(w) "LKLUG"(w) "F
reeSans"(w) "Arial Unicode MS"(w) "Arial Unicode"(w) "Code2000"(w) "Code2001"(w)
"sans-serif"(s) "Arundina Sans"(w) "Roya"(w) "Koodak"(w) "Terafik"(w) "sans-ser
if"(w) "sans-serif"(w) "sans-serif"(w) "sans-serif"(w) "sans-serif"(w) "sans-ser
if"(w) "sans-serif"(w) "sans-serif"(w)
Append list after "DejaVu Sans"(w) "DejaVu LGC Sans"(w) "DejaVu LGC Sans"(w) "B
itstream Vera Sans"(w) "DejaVu Sans"(w) "Verdana"(w) "Arial"(w) "Albany AMT"(w)
"Luxi Sans"(w) "Nimbus Sans L"(w) "Helvetica"(w) "Lucida Sans Unicode"(w) "BPG G
laho International"(w) "Tahoma"(w) "Waree"(w) "Loma"(w) "Waree"(w) "Garuda"(w) "
Umpush"(w) "Laksaman"(w) "Meera"(w) "Khmer OS"(w) "Nachlieli"(w) "Lucida Sans Un
icode"(w) "Yudit Unicode"(w) "Kerkis"(w) "ArmNet Helvetica"(w) "Artsounk"(w) "BP
G UTF8 M"(w) "Waree"(w) "Loma"(w) "Garuda"(w) "Umpush"(w) "Saysettha Unicode"(w)
"JG Lao Old Arial"(w) "GF Zemen Unicode"(w) "Pigiarniq"(w) "B Davat"(w) "B Comp
set"(w) "Kacst-Qr"(w) "Urdu Nastaliq Unicode"(w) "Raghindi"(w) "Mukti Narrow"(w)
"padmaa"(w) "Hapax Berbère"(w) "MS Gothic"(w) "UmePlus P Gothic"(w) "SimSun"(w)
"PMingLiu"(w) "WenQuanYi Zen Hei"(w) "WenQuanYi Bitmap Song"(w) "AR PL ShanHeiS
un Uni"(w) "AR PL New Sung"(w) "MgOpen Moderna"(w) "MgOpen Modata"(w) "MgOpen Co
smetica"(w) "VL Gothic"(w) "IPAMonaGothic"(w) "IPAGothic"(w) "Sazanami Gothic"(w
) "Kochi Gothic"(w) "AR PL KaitiM GB"(w) "AR PL KaitiM Big5"(w) "AR PL ShanHeiSu
n Uni"(w) "AR PL SungtiL GB"(w) "AR PL Mingti2L Big5"(w) "MS ゴシック"(w) "ZYS
ong18030"(w) "NanumGothic"(w) "UnDotum"(w) "Baekmuk Dotum"(w) "Baekmuk Gulim"(w)
"KacstQura"(w) "Lohit Bengali"(w) "Lohit Gujarati"(w) "Lohit Hindi"(w) "Lohit M
arathi"(w) "Lohit Maithili"(w) "Lohit Kashmiri"(w) "Lohit Konkani"(w) "Lohit Nep
ali"(w) "Lohit Sindhi"(w) "Lohit Punjabi"(w) "Lohit Tamil"(w) "Meera"(w) "Lohit
Malayalam"(w) "Lohit Kannada"(w) "Lohit Telugu"(w) "Lohit Oriya"(w) "LKLUG"(w) "
FreeSans"(w) "Arial Unicode MS"(w) "Arial Unicode"(w) "Code2000"(w) "Code2001"(w
) "sans-serif"(s) "Arundina Sans"(w) "Roya"(w) "Koodak"(w) "Terafik"(w) "sans-se
rif"(w) "sans-serif"(w) "sans-serif"(w) "sans-serif"(w) "sans-serif"(w) "sans-se
rif"(w) "sans-serif"(w) "sans-serif"(w)
...
กลายเป็นว่า Waree กลับมาแซงหน้า Loma อีกครั้งหลังจากกฎใน 89-tlwg-waree-synthetic.conf ผลก็คือ ไม่ว่าฟอนต์ไทยตัวไหนจะพยายามลิสต์ตัวเองขึ้นก่อนอย่างไรก็ตาม ก็จะแพ้ฟอนต์ที่ fallback ให้ Tahoma อยู่วันยังค่ำ และการสังเคราะห์ฟอนต์ Tahoma ด้วย Waree ก็ทำให้ Waree ไม่ยอมลงให้กับใคร!
ป้ายกำกับ: thaifonts-scalable, typography






