Thai Font Metrics
ประเด็นเล็ก ๆ ประเด็นหนึ่งที่ถูกอภิปรายกันในหลายโอกาสในหมู่คนทำฟอนต์ไทย หรือกระทั่งในหมู่ผู้ใช้ที่ต้องเตรียมเอกสารให้เข้ากับข้อกำหนด คือเรื่องขนาดของฟอนต์ไทยที่จะเล็กกว่าฟอนต์ตะวันตกที่ point size เดียวกัน เช่น บทความภาษาอังกฤษอาจกำหนดขนาดฟอนต์เป็น 10 หรือ 11 point แต่ถ้าใช้ฟอนต์ไทยขนาดเดียวกันจะเล็กจนอ่านไม่ออก ต้องปรับขนาดเพิ่มเป็น 14 หรือ 16 point ถึงจะเทียบเคียงกันได้ เรื่องนี้คุณเนยสดได้ เขียนอธิบายไว้แล้วเป็นอย่างดี
ฟอนต์จาก TLWG
สำหรับฟอนต์ชุดต่าง ๆ ที่ TLWG ผมได้ปรับขนาดตัวอักษรให้ใหญ่ขึ้น เพื่อให้เข้ากันกับฟอนต์ตะวันตกทั้งหมด ไม่ว่าจะเป็น Fonts-TLWG, Fonts-SIPA-Arundina หรือ ThaiFonts-Siampradesh ทำให้เกิดความไม่เข้ากันกับฟอนต์ไทยอื่น ๆ ที่มีอยู่ในตลาด
สำหรับที่มาที่ไป ผมตัดสินใจใช้ font metrics ที่เข้ากันกับฟอนต์ตะวันตกหลังจากที่ได้พูดคุยกับผู้ใช้และนักพัฒนาใน thread หนึ่งใน gtk-i18n list เมื่อปี 2547 โดยในขณะนั้น ฟอนต์ต่าง ๆ ที่พัฒนา ปรับปรุง และเผยแพร่โดย TLWG ยังใช้ขนาดเหมือนฟอนต์ไทยในตลาด และมีฝรั่งที่พยายามเรียนภาษาไทยบ่นเข้ามาว่าฟอนต์ไทยตัวเล็กมาก อ่านไม่ออก มีฟอนต์ที่ตัวใหญ่กว่านี้แนะนำไหม ผมพยายามอธิบายเหตุผลที่ฟอนต์ไทยต้องตัวเล็ก ว่าเราต้องเผื่อเนื้อที่ให้กับสระบน-ล่างและวรรณยุกต์ ก็ปรากฏว่านักพัฒนา Pango (Owen Taylor) ได้ แนะนำ ว่าสามารถใช้ขนาดตัวอักษรที่เท่ากับฟอนต์ตะวันตกได้ โดยเพียงแต่ขยายระยะระหว่างบรรทัดให้สูงขึ้น และได้รับการ สำทับ จาก Javier Sola นักพัฒนา Khmer OS ว่าฟอนต์ภาษาเขมรก็ใช้วิธีนี้ และได้ผลดี
ในขณะนั้น เรามีฟอนต์ Loma จาก NECTEC ที่เริ่มบุกเบิกทำฟอนต์ UI โดยใช้ metrics ที่สอดคล้องกับฟอนต์ตะวันตกเป็นตัวอย่างอยู่แล้ว หลังจากที่ในวินโดวส์มีฟอนต์ Tahoma ที่ทำงานในลักษณะนี้มาแล้วระยะหนึ่ง เมื่อนำมาประกอบกับข้อมูลที่ได้จากชุมชน GTK+ ดังกล่าว ผมจึงตัดสินใจปรับขนาดฟอนต์ไทยทั้งหมดในแหล่งของ TLWG ตามฟอนต์ตะวันตกตั้งแต่นั้นมา
Font Metrics แบบไทย
ย้อนกลับไปที่ที่มาของ font metrics แบบไทยที่มีการย่อส่วนลงมา เหตุผลเป็นที่เข้าใจได้ไม่ยาก ว่ามาจากการเผื่อเนื้อที่ให้กับสระบน-ล่างและวรรณยุกต์ ทำให้ต้องย่อขนาดของพยัญชนะลง และเพื่อให้เข้ากันกับตัวโรมัน ก็จำเป็นต้องย่อขนาดของตัวโรมันลงตามด้วย ทำให้ตัวโรมันของฟอนต์ไทยมีขนาดเหลือเพียงประมาณ 70% ของฟอนต์ตะวันตกที่มี point size เท่ากัน
เรื่องนี้มีตัวอย่างอย่างละเอียดในหนังสือ แบบตัวพิมพ์ไทย
ที่จัดพิมพ์โดยโครงการฟอนต์แห่งชาติของ NECTEC เมื่อ พ.ศ. 2543

ปัญหา
การใช้ font metrics แบบไทยดูจะทำงานได้ดี และเราก็ใช้งานแบบนี้กันมานาน ตั้งแต่ยุค Windows 3.1 ที่ยังใช้รหัส สมอ. และมี Windows Thai Edition ใช้งานกันอยู่ มาจนถึงยุคเปลี่ยนผ่านสู่ I18N และ Unicode ใน Windows 95, Windows XP แล้วเราก็เริ่มเจออะไรทำนองนี้ในเว็บไซต์:

ภาพนี้ผมจำลองขึ้นใหม่ เนื่องจากไม่มีระบบรุ่นเก่าให้จับภาพแล้ว แต่คงจะพอจำความรู้สึกนี้ได้ ที่เวลาอ่านเว็บไซต์ต่าง ๆ แล้ว เจอข้อความที่ภาษาไทยเล็กเท่ามด ภาษาอังกฤษใหญ่เท่าหม้อข้าว เพราะ text rendering engine แบบ multilingual ยุคแรก ๆ พยายามแสดงข้อความโดยแยกฟอนต์ตามภาษาเขียน แต่มันไม่แยกแยะว่าภาษาไทยต้องขยาย หรือภาษาอังกฤษต้องย่อ ส่วนข้อความภาษาเขมรนั้น ผมจำลองใส่เข้าไปด้วยเพื่อเปรียบเทียบให้ดูว่าเขา implement แบบไหน
rendering engine ยุคหลัง ๆ เริ่มฉลาดขึ้น โดยพยายามเลือกฟอนต์ตามภาษาหลักหรือตามโลแคล ถ้าฟอนต์นั้นมีอักษรโรมันให้ก็นำมาใช้เลย ถ้าไม่มีจึงจะไปหาจากฟอนต์อื่น ช่วยบรรเทาปัญหาข้อความผสมภาษาไทย-อังกฤษลงได้
แล้วโลกก็หมุนต่อไป สังคมไทยเริ่มเข้าสู่ยุคที่มีภาษาที่สามที่สี่ เด็ก ๆ เริ่มเรียนภาษาจีน ญี่ปุ่น เกาหลี ฯลฯ กันมากขึ้น ประชาคมเศรษฐกิจอาเซียนเริ่มรวมตัวกัน เริ่มมีข้อความภาษาลาว เขมร พม่า เข้ามามากขึ้น การใช้งานแบบ multilingual เริ่มเข้มข้นขึ้นกว่าแต่ก่อนที่เคยมีแค่ไทย-อังกฤษ
คำถามคือ เราจะจัดการระบบ multilingual นี้อย่างไร? เดิมมีแค่สองภาษา ฟอนต์อังกฤษมันโตเกินไป เราก็เพิ่มอักษรอังกฤษย่อส่วนลงในฟอนต์ไทยเสียก็สิ้นเรื่อง แต่เมื่อมีภาษาจีน ญี่ปุ่น เกาหลี ลาว เขมร พม่า เข้ามาร่วมด้วย เราจะเพิ่มอักษรของภาษาเหล่านั้นลงในฟอนต์ไทยหมดไหม? เอาแค่อักษรจีนอย่างต่ำ 5,000 ตัวก็อ่วมอรไทแล้ว ไหนจะอักษรเขมรที่มีอักษรตัวเชิง ทำให้ต้องเผื่อเนื้อที่บน-ล่างกว้างกว่าอักษรไทยเสียอีก เราจะได้ฟอนต์ตัวเล็กลงไปอีก และถ้าสักวันเราจะเพิ่ม อักษรทิเบต (ไม่แน่นะครับ ก็เราชอบประเทศภูฏานกันมากไม่ใช่หรือ) ที่ซ้อนกันสนุกสนานกว่าอักษรเขมรเสียอีก เราจะยิ่งได้ฟอนต์ที่เล็กกระจิ๋วหลิวเลยทีเดียว
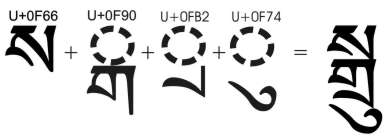
เริ่มเห็นภาพกันไหมครับ ว่าการเผื่อช่องว่างสำหรับการซ้อนอักขระมันไม่ scale ในระบบ multilingual
หรือหากผลักภาระไปให้ rendering engine ที่จะต้องจดจำว่าภาษาแต่ละภาษาต้องย่อ-ขยายด้วยอัตราเท่าไรแล้วปรับขนาดฟอนต์เอา มันก็เป็น workaround ที่ไปเพิ่มความยุ่งยากให้กับการออกแบบฟอนต์คู่สองภาษาอื่น ๆ เช่น การสร้างฟอนต์ที่มีอักษรไทย-ลาว, ไทย-เขมร, ไทย-พม่า, ไทย-ยาวี เพื่อใช้ในบริบทของกลุ่มผู้ใช้ทวิภาษา จะต้องออกแบบฟอนต์ให้อักษรแต่ละภาษามีขนาดไม่เท่ากันในฟอนต์เดียวกัน และถ้าเกิดว่า rendering engine ของแต่ละระบบใช้อัตราย่อ-ขยายของแต่ละภาษาต่างกันอีกล่ะ? คงจะพอจินตนาการถึงความยุ่งยากกันได้ และโชคดีที่ไม่มี rendering engine ไหนคิดทำอะไรทำนองนี้
ถ้าเช่นนั้น แบบไหนล่ะถึงจะ scale?
ทางออก
ระบบที่ดูสมเหตุสมผลกว่าก็คือ ทุกภาษาควรอิงบรรทัดฐานเดียวกัน กล่าวคือ
กำหนดให้ point size คือความสูงของตัวอักษร ไม่ใช่ความสูงของบรรทัด
เมื่อกำหนดอย่างนี้ แล้วไปขยายขนาดตัวอักษรไทยทั้งหมดให้สูงเท่า point size ซึ่งจะทำให้วรรณยุกต์เขยิบขึ้นสูงจนตกขอบด้านบนของ em-box นักพัฒนาฟอนต์ก็อาจเกิดประเด็นคำถามต่อไปนี้:
- จะกำหนดความสูงของบรรทัดให้สูงกว่า em-box ได้อย่างไร?
- การที่ glyph ของวรรณยุกต์ตกขอบ em-box ซึ่งเป็น bounding box ออกไป จะไม่ผิดหลักการหรือ?
- font metrics แบบใหม่ จะขัดกันกับแบบเดิมที่ใช้ในเอกสารต่าง ๆ ไหม?
ก็จะตอบทีละประเด็นนะครับ
การกำหนดความสูงของบรรทัด
โดยปกติที่ผ่านมา ฟอนต์ไทยเคร่งครัดกับเรื่องความสูงของบรรทัดที่จะไม่ให้เกิน em-box ทำให้เราต้องย่อขนาดตัวอักษรทั้งหมดให้เล็กลงเพื่อให้สามารถบรรจุสระบน-ล่างและวรรณยุกต์ลงไปใน em-box ได้
แต่ในการคำนวณระยะระหว่างบรรทัดของโปรแกรมต่าง ๆ ที่ใช้ฟอนต์ TrueType หรือ OpenType จะไม่ได้ใช้ ascender/descender จาก em-box นี้โดยตรง แต่จะใช้ค่า sTypoAscender, sTypoDescender และ sTypoLineGap จาก ตาราง OS/2 & Windows Metrics ในตัวฟอนต์ ซึ่งเราสามารถกำหนดค่า sTypoAscender และ sTypoDescender ให้เลย em-box ออกไปได้ และอาจกำหนดค่า usWinAscent และ usWinDescent ด้วย เพื่อไม่ให้บิตแม็ปของตัวอักษรที่วาดถูกขลิบออก
อย่างไรก็ดี ในทางปฏิบัติแล้ว ค่า usWinAscent และ usWinDescent กลับเป็นค่าที่มีผลต่อการคำนวณระยะระหว่างบรรทัดมากกว่า (app ต่าง ๆ ไม่ได้ทำตาม spec ของไมโครซอฟท์นัก แม้ใน spec ของไมโครซอฟท์จะเขียนไว้ว่า This is strongly discouraged.
ก็ตาม
โดยสรุปก็คือ ควรกำหนดค่าทั้ง sTypoAscender, sTypoDescender, usWinAscent, usWinDescent ทั้งหมดไว้ก่อน
หากใช้ Fontforge ก็กำหนดได้ในแท็บ OS/2 Metrics (Element > Font Info > OS/2 > Metrics)

ตำแหน่งของวรรณยุกต์
ในยุคก่อน เรามีการจัดตำแหน่งสระบน-ล่างและวรรณยุกต์เพื่อหลบหางพยัญชนะโดยใช้วิธีสร้าง glyph ชุดพิเศษที่มีการเลื่อนตำแหน่งรอไว้ แล้ว rendering engine จะเลือกใช้ glyph ชุดพิเศษเหล่านั้นตามความเหมาะสม เป็นเทคนิคที่เขาเรียกกันว่า positioning by substitution
glyph ชุดพิเศษต่าง ๆ เหล่านี้ จะเลื่อนระยะไว้เรียบร้อยเพื่อให้นำไปวางซ้อนได้พอดีโดยไม่มีการเลื่อนที่อีก ดังนั้น หากจะใช้เทคนิคนี้กับฟอนต์ที่ขยายขนาดขึ้น glyph ของวรรณยุกต์ที่เลื่อนระยะรอไว้ก็จะต้องตกขอบ em-box อย่างเลี่ยงไม่ได้ (แต่ยังอยู่ภายในความสูงของบรรทัด)
แต่นั่นเป็นข้อจำกัดของระบบเก่าก่อนที่จะมี OpenType
ด้วยเทคโนโลยี OpenType เรามีเครื่องมือจัดตำแหน่งการวางซ้อนอักขระ โดยใช้ข้อมูล GPOS ซึ่งอาศัยการกำหนด anchor สำหรับวาง glyph ซ้อนกันเหมือนการต่อชิ้นส่วนเลโก้ โดย glyph ที่เป็นฐานจะมี base anchor เป็นเหมือนเบ้าเสียบรอไว้ ส่วน glyph ที่จะมาวางซ้อนก็จะมี mark anchor เป็นเหมือนเดือยสำหรับเสียบเข้ากับเบ้า
ในการวาง glyph ที่มาซ้อนนั้น ตำแหน่ง glyph ตัวสวมจะถูกเลื่อนที่ด้วยเวกเตอร์ระหว่าง anchor เสียบกับ anchor เบ้า เพื่อให้ anchor สวมกันได้พอดี ดังนั้น ตำแหน่งเดิมของ glyph จะอยู่ที่ไหนก็ไม่สำคัญ เพราะยังไงก็สามารถคำนวณเวกเตอร์ดังกล่าวได้อยู่แล้ว ทำให้เราสามารถวาง glyph ของวรรณยุกต์ไว้ภายใน em-box ก็ได้ถ้าต้องการ นักพัฒนาฟอนต์ที่เคร่งครัดกับ em-box จึงวางใจได้
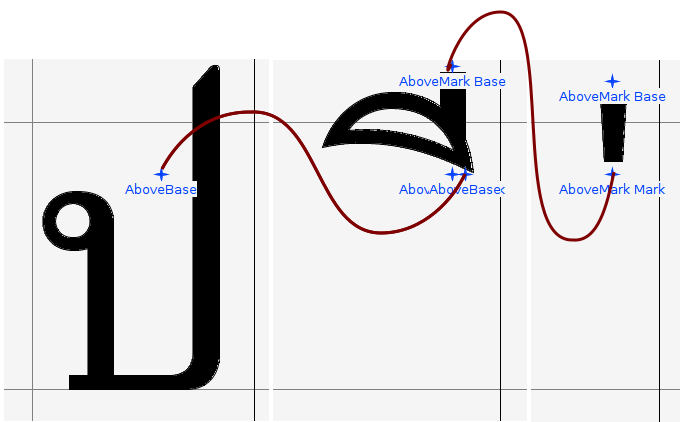
สำหรับผู้ที่สนใจ ไมโครซอฟท์มีเอกสารแนะนำ การสร้างฟอนต์ OpenType สำหรับอักษรไทย โดยเฉพาะ
ความเข้ากันได้กับฟอนต์เดิม
ประเด็นนี้ ตอบได้สั้น ๆ ว่า ไม่เข้ากันแน่นอน
หากจะเปลี่ยนมาใช้ metrics ใหม่ จะต้องมีการจัดการกับความเปลี่ยนแปลง และคงไม่ใช่เรื่องที่จะทำได้ชั่วข้ามคืน ผมเองก็ไม่เคยคิดว่ามันจะเกิดในอนาคตอันใกล้ จนกระทั่งเริ่มสังเกตเห็นแนวโน้มความเปลี่ยนแปลงบางอย่าง กล่าวคือ
- ฟอนต์นานาภาษา ที่มีอักษรของภาษาต่าง ๆ ทั่วโลกเริ่มมีมากขึ้น หลังจากเทคโนโลยี multilingual เริ่มอยู่ตัวและใช้กันเป็นปกติ เช่น
- Freefont จาก GNU Project (มีอักษรไทย)
- Noto Fonts จาก Google (มีอักษรไทย)
- DejaVu fork จาก Bitstream Vera (ยังไม่มีอักษรไทย)
- web font ไทย
- คัดสรร ดีมาก (Cadson Demak) เท่าที่ตรวจสอบเฉพาะ 3 ฟอนต์ใน Google Fonts พบว่าใช้ font metrics ที่ point size = ขนาดตัวอักษร และใช้ GPOS ในการเลื่อนวรรณยุกต์ขึ้นสูงจาก em-box
หากแนวโน้มการสร้างฟอนต์นานาภาษาเพื่อใช้ในระบบต่าง ๆ มีมากขึ้น (ผมยังไม่ได้ตรวจสอบฟอนต์ที่ใช้ในสมาร์ทโฟนต่าง ๆ) และการใช้ฟอนต์ในเว็บไซต์ต่าง ๆ ก็มีมากขึ้น จึงน่าสนใจว่าแนวโน้มเหล่านี้จะมีผลเปลี่ยนแปลงการใช้ฟอนต์ในเดสก์ท็อปปัจจุบันมากน้อยแค่ไหน คงต้องรอดูกันต่อไป โดยเฉพาะบนวินโดวส์ที่มีฟอนต์ Tahoma ให้ใช้กันเป็นตัวอย่างมานานแล้ว
และสุดท้ายก็อยู่ที่ผู้พัฒนาฟอนต์ทั้งหลายนั่นแหละครับ ว่าจะขยับไปสู่แนวทางนี้กันมากน้อยแค่ไหน
ป้ายกำกับ: thaifonts-scalable, typography
บันทึกโดย Thep ณ
17:10
1 ความเห็น
![]()





